- Published on
100 bài luyện tập xử lý ngôn ngữ tự nhiên
- Authors
- Name
- Kevin Nguyen


Dịch từ tài liệu 言語処理 100 本ノック 2020 của lab Inui-Okazaki, đại học Tohoku, Nhật Bản. Người dịch: Phạm Quang Nhật Minh (minhpqn).
Note: Khác với phiên bản 2005, phiên bản 2020 bổ sung 3 chương 8, 9, 10 về các nội dung liên quan đến mô hình Neural Networks.
Các lời giải được sưu tầm1
Chương 1: Bài tập khởi động

00. Đảo ngược xâu ký tự
Đảo ngược xâu ký tự "stressed" (theo thứ tự từ cuối xâu đến đầu xâu ký tự).
s = "stressed"
r_s = "".join([c for c in reversed(s)])
print(r_s)
desserts
01. "schooled"
Tạo một xâu kí tự bằng cách nối các kí tự ở vị trí 1, 3, 5, 7 trong xâu kí tự "schooled".
s = "schooled"
ret_s = "".join([c for c in s[1:8:2]])
print(ret_s)
cold
02. "shoe" + "cold" = "schooled"
Tạo xâu kí tự "schooled" bằng cách nối các kí tự trong "shoe" và "cold" luân phiên nhau từ đầu đến cuối.
s1="shoe"
s2="cold"
s = "".join([c1+c2 for c1, c2 in zip(s1, s2)])
print(s)
schooled
03. Pi
Tách câu "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." thành các từ và tạo ra một danh sách (list) mà mỗi thành phần của nó biểu thị số các kí tự alphabet trong từ tương ứng.
s = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."
for word in s.strip().split(' '):
print("----{}----".format(word))
c_count = {}
for c in word:
#print(c)
if c in c_count:
c_count[c] += 1
else:
c_count[c] = 1
for k, v in sorted(c_count.items(), key=lambda x:x[1], reverse=True):
print(k, v)
----Now----
N 1
o 1
w 1
----I----
I 1
----need----
e 2
n 1
d 1
----a----
a 1
----drink,----
d 1
r 1
i 1
n 1
k 1
, 1
----alcoholic----
l 2
c 2
o 2
a 1
h 1
i 1
----of----
o 1
f 1
----course,----
c 1
o 1
u 1
r 1
s 1
e 1
, 1
----after----
a 1
f 1
t 1
e 1
r 1
----the----
t 1
h 1
e 1
----heavy----
h 1
e 1
a 1
v 1
y 1
----lectures----
e 2
l 1
c 1
t 1
u 1
r 1
s 1
----involving----
i 2
n 2
v 2
o 1
l 1
g 1
----quantum----
u 2
q 1
a 1
n 1
t 1
m 1
----mechanics.----
c 2
m 1
e 1
h 1
a 1
n 1
i 1
s 1
. 1
04. Atomic symbols
Tách câu "Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can." thành các từ và trích xuất kí tự đầu tiên của các từ ở vị trí 1, 5, 6, 7, 8, 9, 15, 16, 19 và hai kí tự đầu tiên của các từ còn lại. Tạo một mảng kết hợp (đối tượng dạng dictionary hoặc mapping) ánh xạ từ xâu được trích xuất tới vị trí (offset ở trong câu) của từ tương ứng.
pop_idx_1 = [1, 5, 6, 7, 8, 9, 15, 16, 19]
s = "Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can."
ret = {}
for i, word in enumerate(s.strip().split(' ')):
if i+1 in pop_idx_1:
ret[i] = word[0]
elif len(word) > 1:
ret[i] = word[1]
print(ret)
{0: 'H', 1: 'e', 2: 'i', 3: 'e', 4: 'B', 5: 'C', 6: 'N', 7: 'O', 8: 'F', 9: 'e', 10: 'a', 11: 'i', 12: 'l', 13: 'i', 14: 'P', 15: 'S', 16: 'l', 17: 'r', 18: 'K', 19: 'a'}
05. n-gram
Viết hàm sinh ra tất cả các n-gram từ một dãy cho trước (xâu kí tự hoặc danh sách). Sử dụng hàm đã viết, sinh ra word bi-gram và character bi-gram từ câu "I am an NLPer"
def get_ngram(s, N):
words = s.strip().split(' ')
word_bi_gram = [words[i: i + N] for i in range(len(words) - N + 1)]
letter_bi_gram = [s[i: i + N] for i in range(len(s) - N + 1)]
return word_bi_gram, letter_bi_gram
s = "I am an NLPer"
get_ngram(s, 2)
([['I', 'am'], ['am', 'an'], ['an', 'NLPer']],
['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er'])
06. Tập hợp
- Sinh ra tập X và Y tương ứng là tập các character bi-gram từ hai xâu ký tự "paraparaparadise" và "paragraph".
- Sinh ra các tập hợp union, intersection và difference của X và Y
- Kiểm tra xem bi-gram 'se' có thuộc tập X và Y hay không?
def get_ngram(s, N, mode='leter'):
words = s.strip().split(' ')
if mode == 'word':
bi_gram = [words[i: i + N] for i in range(len(words) - N + 1)]
elif mode == 'leter':
bi_gram = [s[i: i + N] for i in range(len(s) - N + 1)]
return bi_gram
X = set(get_ngram(s="paraparaparadise", N=2, mode='leter'))
Y = set(get_ngram(s="paragraph", N=2, mode='leter'))
print(X, Y)
print(X.union(Y))
print(X.intersection(Y))
print(X.difference(Y))
print('se' in X)
print('se' in Y)
{'ap', 'ar', 'ad', 'is', 'pa', 'se', 'di', 'ra'} {'ra', 'ph', 'ap', 'ar', 'gr', 'pa', 'ag'}
{'ph', 'ap', 'ar', 'gr', 'ad', 'is', 'pa', 'ag', 'se', 'di', 'ra'}
{'ap', 'ar', 'pa', 'ra'}
{'di', 'is', 'se', 'ad'}
True
False
07. Sinh ra câu từ template
Viết hàm số nhận vào 3 biến x, y, z và trả về xâu ký tự "y vào lúc x giờ là z", trong đó x, y và z thể hiện giá trị của x, y, z. Sinh ra kết quả với các giá trị x, y, z sau đây x="12" y="Nhiệt độ" z=22.4
def generate(x, y, z):
return '%s vào lúc %s giờ là %s' %(str(y), str(x), str(z))
def main():
print(generate(12,"Nhiệt độ", 22.4))
if __name__ == '__main__':
main()
Nhiệt độ vào lúc 12 giờ là 22.4
08. Xâu mật mã
Từ các ký tự của một xâu cho trước, cài đặt hàm có tên cipher để mã hoá xâu như sau:
- Mọi ký tự tiếng Anh ở dạng thường (lower-case characters) c được chuyển thành ký tự có mã là (219 - [mã ký tự ASCII của c]).
- Các ký tự khác giữ nguyên.
Sử dụng hàm đã viết để mã hoá và giải mã các xâu ký tự tiếng Anh.
import re
lowerReg = re.compile(r'^[a-z]+$')
def cipher(s):
if lowerReg.match(s):
return "".join([chr(219 - ord(c)) for c in s])
else:
return s
print(cipher(s='cipher'))
xrksvi
09. Typoglycemia
Viết chương trình thực hiện việc sau:
- Nhận đầu vào là một câu tiếng Anh bao gồm các word ngăn cách nhau bằng ký tự space.
- Với mỗi word trong câu:
- Nếu word đó không có nhiều hơn 4 kí tự, giữ nguyên word đó
- Nếu không,
- Giữ nguyên kí tự đầu và kí tự cuối của word
- Đảo thứ tự một cách ngẫu nhiên các kí tự ở những vị trí khác (ở giữa của word đó).
Cho trước một câu tiếng Anh hợp lệ, ví dụ "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .", chạy chương trình đã viết để đưa ra kết quả.
import random
def typoglycemia(s):
words = [word for word in s.strip().split(' ')]
if len(word) <= 4:
return s
ret = words[1:-2]
random.shuffle(ret)
ret.insert(0, words[0])
ret.append(words[-1])
return " ".join(ret)
print(typoglycemia(s = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ."))
print(typoglycemia(s ="a b c d"))
I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .
a b c d
Chương 2: Các lệnh cơ bản trên môi trường UNIX

Tệp popular-names.txt là một tệp ở định dạng phân cách bằng dấu tab, lưu trữ "tên", "giới tính", "số người" và "năm sinh" của các em bé được sinh ra ở Hoa Kỳ. Viết chương trình thực hiện các xử lý sau đây. Tệp popular-names.txt là đầu vào của của chương trình. Sau đó, chỉ dùng cách lệnh trong UNIX để thực hiện cùng các nhiệm vụ và xác nhận xem kết quả các lệnh UNIX đưa ra có giống với kết quả của chương trình bạn viết hay không.
!wget https://nlp100.github.io/data/popular-names.txt
10. Đếm số dòng trong file
Đếm số dòng trong file. Xác nhận kết quả bằng lệnh wc trong unix.
input_file = 'popular-names.txt'
with open(input_file, 'r') as f:
print(sum([1 for _ in f]))
!wc -l $input_file
2780
2780 popular-names.txt
11. Biến đổi các ký tự tab thành space
Chuyễn mỗi ký tự tab thành ký tự space. Xác nhận kết quả bằng các lệnh sed, tr hoặc expand.
input_file = 'popular-names.txt'
with open(input_file, 'r') as f:
for row in f:
row.replace('\t', ' ')
12. Lưu cột 1 vào file col1.txt, cột 2 vào file col2.txt
Trích xuất nội dung trong cột 1, cột 2 của các dòng trong file và lưu vào các file tương ứng: col1.txt và col2.txt. Thử thực hiện công việc với lệnh cut trong unix.
input_file = 'popular-names.txt'
with open(input_file, 'r') as input_f, \
open('col1.txt', 'w') as output_f1, \
open('col2.txt', 'w') as output_f2:
for row in input_f:
l = row.strip().split('\t')
output_f1.write(l[0] + '\n')
output_f2.write(l[1] + '\n')
!head $input_file
!head 'col1.txt'
!head 'col2.txt'
Mary F 7065 1880
Anna F 2604 1880
Emma F 2003 1880
Elizabeth F 1939 1880
Minnie F 1746 1880
Margaret F 1578 1880
Ida F 1472 1880
Alice F 1414 1880
Bertha F 1320 1880
Sarah F 1288 1880
Mary
Anna
Emma
Elizabeth
Minnie
Margaret
Ida
Alice
Bertha
Sarah
F
F
F
F
F
F
F
F
F
F
13. Trộn hai file col1.txt và col2.txt
Kết hợp nội dung trong 2 file col1.txt và col2.txt đã được tạo ra trong bài 12 để tạo thành một file mới có nội dung gồm cột 1 và cột 2 trong file ban đầu và các cột cách nhau bởi ký tự tab. Sử dụng lệnh paste để thực hiện bài tập và xác nhận kết quả của chương trình bạn viết.
with open('col1.txt', 'r') as input_f1, \
open('col2.txt', 'r') as input_f2, \
open('merge_col1_col2.txt', 'w') as output_f:
for row1, row2 in zip(input_f1, input_f2):
output_f.write("{}\t{}\n".format(row1.strip(), row2.strip()))
! head 'merge_col1_col2.txt'
Mary F
Anna F
Emma F
Elizabeth F
Minnie F
Margaret F
Ida F
Alice F
Bertha F
Sarah F
14. Trích xuất ra N hàng đầu tiên của file
Viết chương trình trích xuất ra N hàng đầu tiên của file. Biến số dòng lệnh là số tự nhiên N. Sử dụng lệnh head trong unix để thực hiện công việc.
def head(input_file, N):
with open(input_file, 'r') as f:
for row in f.readlines()[0:N]:
print(row.strip())
input_file = 'popular-names.txt'
head(input_file, N=5)
Mary F 7065 1880
Anna F 2604 1880
Emma F 2003 1880
Elizabeth F 1939 1880
Minnie F 1746 1880
15. Trích xuất ra N hàng cuối cùng của file
Viết chương trình trích xuất ra N hàng cuối cùng của file. Chương trình nhận đầu vào từ dòng lệnh số tự nhiên N. Sử dụng lệnh tail trong unix để thực hiện công việc.
def tail(input_file, N):
with open(input_file, 'r') as f:
for row in f.readlines()[-N::1]:
print(row.strip())
input_file = 'popular-names.txt'
tail(input_file, N=3)
! tail -n 3 $input_file
Lucas M 12585 2018
Mason M 12435 2018
Logan M 12352 2018
Lucas M 12585 2018
Mason M 12435 2018
Logan M 12352 2018
16. Chia file thành N phần
Nhận một số tự nhiên N từ đối số của dòng lệnh và chia file đầu vào thành N phần tại các ranh giới của các dòng (line boundaries). Xác nhận lại kết quả bằng lệnh split trong UNIX.
def split_line(input_file, N):
with open(input_file, 'r') as f:
l = f.readlines()
step = 1
for i in range(0, len(l), N):
step+=1
print('---step({})---'.format(step))
for data in l[i:i+N]:
print(data.strip())
input_file = 'popular-names.txt'
split_line(input_file, N=3)
! tail -n 6 $input_file
17. Các xâu phân biệt trong cột đầu tiên
Tìm các xâu phân biệt (một tập hợp các xâu) của cột đầu tiên của file. Xác nhận lại kết quả bằng cách dùng lệnh cut, sort và uniq.
def set_strings(input_file):
s = set()
with open(input_file, 'r') as f:
for row in f:
l = row.strip().split('\t')
s.add(l[0])
print(s)
input_file = 'popular-names.txt'
set_strings(input_file)
{'William', 'Amelia', 'Frank', 'Barbara', 'Noah', 'Abigail', 'George', 'Amy', 'Ava', 'Stephanie', 'Megan', 'Crystal', 'Elijah', 'Joan', 'Walter', 'Florence', 'Henry', 'Christopher', 'Mia', 'Betty', 'Tammy', 'Kathleen', 'Marie', 'Thomas', 'Julie', 'Pamela', 'Brian', 'Harper', 'Rebecca', 'Justin', 'Anthony', 'Joseph', 'Elizabeth', 'Doris', 'Isabella', 'Emma', 'Benjamin', 'Rachel', 'Jeffrey', 'Andrew', 'Linda', 'Dorothy', 'Daniel', 'Bessie', 'Frances', 'Judith', 'Ashley', 'Nicholas', 'Ronald', 'Karen', 'Alice', 'Kimberly', 'Steven', 'Oliver', 'Carolyn', 'Minnie', 'Laura', 'Logan', 'Deborah', 'Liam', 'Lisa', 'Anna', 'Matthew', 'Brandon', 'Lauren', 'Aiden', 'Angela', 'Lillian', 'Mary', 'Sandra', 'Cynthia', 'James', 'Susan', 'Donald', 'Ida', 'Amanda', 'Clara', 'Ruth', 'David', 'Jason', 'Scott', 'Harry', 'Chloe', 'Nancy', 'Ethan', 'Shirley', 'Richard', 'Hannah', 'Alexis', 'Sarah', 'Austin', 'Evelyn', 'Michael', 'Emily', 'Mark', 'Heather', 'Mason', 'Olivia', 'Helen', 'John', 'Edward', 'Lucas', 'Samantha', 'Ethel', 'Margaret', 'Debra', 'Nicole', 'Jayden', 'Donna', 'Madison', 'Alexander', 'Jennifer', 'Jacob', 'Lori', 'Brittany', 'Michelle', 'Carol', 'Joshua', 'Gary', 'Charlotte', 'Charles', 'Jessica', 'Virginia', 'Melissa', 'Mildred', 'Kelly', 'Patricia', 'Sharon', 'Tracy', 'Annie', 'Robert', 'Bertha', 'Sophia', 'Larry', 'Tyler', 'Taylor'}
18. Sắp xếp các dòng theo thứ tự giảm dần của cột thứ 3
Sắp xếp các dòng theo thứ tự giảm dần của các số trong cột thứ 3 (sắp xếp các dòng nhưng không thay đổi nội dung của trong mỗi dòng). Xác nhận lại kết quả với lệnh sort.
def reverse_col3(input_file):
ret = []
with open(input_file, 'r') as f:
for row in f:
l = row.strip().split('\t')
ret.append(int(l[2]))
print(sorted(ret, reverse=True))
input_file = 'popular-names.txt'
reverse_col3(input_file)
[99689, 96211, 94757, 92704, 91640, 91016, 90656, 90517, 88584, 88528, 88327, 88319, 87436, 87261, 87063, 86917, 86857, 86604, 86351, 86298, 86272, 86256, 86253, 86224, 86099, 85929, 85475, 85302, 85251, 85203, 85034, 84863, 84758, 84275, 84226, 84180, 84155, 84138, 83931, 83917, 83872, 83782, 83703, 83559, 83138, 82829, 82646, 82578, 82533, 82436, 82349, 82008, 81717, 81624, 81574, 81324, 81165, 81161, 81021, 80790, 80431, 80261, 80190, 80054, 79990, 79929, 79529, 79424, 79261, 79049, 78984, 78713, 78625, 78606, 78467, 78429, 77594, 77272, 77176, 76951, 76832, 76407, 76152, 76093, 75991, 75924, 75054, 74865, 74502, 74449, 73985, 73978, 73534, 73037, 72901, 72797, 72555, 72360, 72173, 71838, 71750, 71687, 71638, 71541, 71405, 71322, 70982, 70843, 70639, 70591, 70196, 70012, 70003, 69937, 68919, 68763, 68696, 68597, 68454, 68235, 68007, 68000, 67852, 67847, 67832, 67741, 67739, 67701, 67616, 67578, 67467, 67366, 67158, 67082, 66989, 66954, 66872, 66864, 66810, 66736, 66610, 66420, 66169, 66113, 66027, 65838, 65721, 65634, 65481, 65389, 65290, 65174, 65144, 65032, 64912, 64792, 64379, 64281, 64233, 64208, 64146, 64143, 63718, 63700, 63655, 63603, 63508, 63254, 63165, 63123, 63114, 63047, 62782, 62473, 62467, 62447, 62268, 62149, 61965, 61840, 61835, 61759, 61756, 61752, 61698, 61669, 61618, 61501, 61438, 61417, 61280, 61196, 61130, 61094, 60929, 60897, 60801, 60785, 60727, 60699, 60693, 60689, 60508, 60296, 60269, 60046, 60038, 60029, 59958, 59915, 59874, 59798, 59645, 59627, 59609, 59601, 59474, 59349, 59330, 59283, 59266, 59231, 59099, 59055, 58964, 58957, 58868, 58771, 58728, 58525, 58521, 58492, 58403, 58375, 58350, 58325, 58217, 58211, 58187, 58183, 58040, 57806, 57767, 57515, 57470, 57277, 57203, 57199, 57117, 57049, 57014, 56929, 56914, 56913, 56909, 56829, 56783, 56717, 56691, 56623, 56558, 56551, 56524, 56442, 56381, 56321, 56215, 56203, 56117, 56110, 56040, 55994, 55954, 55898, 55857, 55829, 55653, 55645, 55509, 55381, 55069, 55000, 54901, 54884, 54854, 54779, 54776, 54686, 54677, 54621, 54549, 54493, 54474, 54392, 54372, 54346, 54275, 54249, 54218, 54195, 53941, 53793, 53755, 53674, 53545, 53528, 53511, 53504, 53304, 53209, 53178, 53118, 53098, 52997, 52939, 52906, 52794, 52784, 52754, 52710, 52682, 52680, 52677, 52665, 52564, 52435, 52434, 52401, 52369, 52336, 52315, 52201, 52189, 52186, 52136, 52127, 52113, 51922, 51920, 51860, 51853, 51629, 51543, 51518, 51482, 51475, 51366, 51288, 51279, 51219, 51116, 51102, 51018, 51015, 51000, 50970, 50939, 50677, 50654, 50559, 50556, 50519, 50501, 50463, 50408, 50235, 50217, 50213, 50149, 50043, 49963, 49942, 49814, 49801, 49776, 49748, 49676, 49549, 49532, 49350, 49350, 49146, 49117, 49092, 48832, 48792, 48746, 48676, 48652, 48617, 48603, 48423, 48347, 48321, 48302, 48284, 48234, 48171, 48075, 47994, 47945, 47912, 47884, 47837, 47805, 47789, 47680, 47669, 47589, 47576, 47499, 47402, 47265, 47259, 47169, 47158, 47151, 47104, 47083, 47079, 47007, 47005, 46925, 46826, 46749, 46734, 46683, 46592, 46571, 46481, 46475, 46439, 46366, 46330, 46328, 46296, 46222, 46217, 46157, 46136, 46078, 46066, 46043, 45948, 45890, 45870, 45855, 45824, 45642, 45599, 45560, 45451, 45374, 45345, 45290, 45282, 45269, 45210, 45202, 45173, 45122, 45029, 44860, 44835, 44818, 44804, 44768, 44734, 44572, 44500, 44474, 44469, 44297, 44240, 44091, 43971, 43778, 43585, 43546, 43486, 43478, 43429, 43398, 43342, 43333, 43276, 43219, 43181, 43037, 42889, 42737, 42702, 42651, 42651, 42601, 42533, 42460, 42422, 42422, 42390, 42358, 42222, 42195, 42118, 42117, 42078, 42077, 42064, 42052, 41931, 41925, 41899, 41815, 41786, 41772, 41640, 41599, 41552, 41550, 41462, 41402, 41354, 41350, 41218, 41181, 41117, 41102, 41027, 40990, 40786, 40770, 40713, 40704, 40668, 40632, 40620, 40620, 40586, 40543, 40529, 40459, 40419, 40403, 40276, 40262, 40228, 40198, 40170, 40127, 40097, 40071, 40054, 40047, 40042, 40000, 39999, 39915, 39865, 39625, 39591, 39538, 39457, 39456, 39409, 39397, 39386, 39371, 39326, 39325, 39294, 39279, 39273, 39270, 39203, 39199, 39197, 39177, 39176, 39106, 39102, 39087, 39054, 39052, 39049, 39044, 38963, 38910, 38875, 38869, 38867, 38772, 38756, 38701, 38676, 38570, 38564, 38542, 38521, 38486, 38472, 38463, 38453, 38439, 38434, 38412, 38397, 38364, 38356, 38313, 38309, 38276, 38264, 38253, 38234, 38227, 38203, 38163, 38028, 38017, 37948, 37940, 37919, 37855, 37821, 37788, 37734, 37716, 37706, 37638, 37629, 37619, 37551, 37549, 37542, 37521, 37451, 37446, 37415, 37381, 37339, 37311, 37258, 37236, 37147, 37098, 37031, 36972, 36956, 36901, 36877, 36860, 36849, 36827, 36819, 36786, 36776, 36734, 36707, 36675, 36643, 36642, 36627, 36617, 36615, 36574, 36537, 36533, 36524, 36465, 36380, 36370, 36354, 36322, 36215, 36206, 36185, 36148, 36105, 36080, 36060, 36016, 35987, 35985, 35894, 35865, 35861, 35857, 35843, 35839, 35821, 35770, 35743, 35741, 35715, 35698, 35657, 35579, 35569, 35517, 35503, 35434, 35432, 35422, 35420, 35373, 35363, 35335, 35314, 35279, 35220, 35220, 35218, 35184, 35161, 35115, 35097, 35097, 35042, 35001, 34987, 34938, 34925, 34912, 34887, 34850, 34822, 34811, 34806, 34800, 34775, 34750, 34705, 34700, 34697, 34654, 34477, 34469, 34460, 34451, 34425, 34417, 34408, 34406, 34380, 34373, 34322, 34310, 34284, 34280, 34270, 34251, 34227, 34217, 34214, 34187, 34153, 34136, 34132, 34052, 34050, 34040, 34037, 34026, 34006, 33998, 33945, 33921, 33912, 33908, 33889, 33856, 33818, 33810, 33775, 33754, 33749, 33743, 33731, 33706, 33702, 33702, 33657, 33648, 33605, 33588, 33581, 33572, 33539, 33521, 33518, 33487, 33396, 33394, 33293, 33221, 33218, 33160, 33157, 33153, 33102, 33077, 32987, 32973, 32964, 32946, 32937, 32909, 32875, 32872, 32865, 32843, 32813, 32746, 32732, 32703, 32703, 32674, 32664, 32662, 32653, 32643, 32637, 32617, 32545, 32510, 32508, 32502, 32485, 32462, 32454, 32444, 32349, 32344, 32304, 32298, 32251, 32240, 32234, 32183, 32117, 32104, 32090, 32073, 32037, 32032, 31973, 31954, 31936, 31930, 31928, 31925, 31908, 31871, 31869, 31855, 31816, 31809, 31798, 31773, 31741, 31740, 31734, 31719, 31692, 31687, 31684, 31682, 31682, 31636, 31623, 31611, 31598, 31532, 31526, 31515, 31514, 31500, 31492, 31492, 31488, 31477, 31468, 31459, 31373, 31372, 31349, 31341, 31337, 31247, 31192, 31142, 31138, 31137, 31129, 31106, 31098, 31095, 31085, 31060, 31003, 30994, 30921, 30917, 30901, 30866, 30826, 30787, 30732, 30718, 30696, 30696, 30642, 30641, 30618, 30608, 30599, 30574, 30551, 30535, 30532, 30529, 30524, 30515, 30507, 30477, 30461, 30456, 30456, 30415, 30414, 30409, 30409, 30387, 30347, 30317, 30278, 30273, 30264, 30247, 30229, 30212, 30207, 30203, 30202, 30167, 30128, 30065, 30017, 29983, 29981, 29939, 29931, 29924, 29899, 29856, 29853, 29834, 29796, 29792, 29786, 29753, 29706, 29687, 29683, 29661, 29638, 29622, 29616, 29587, 29582, 29569, 29565, 29552, 29521, 29487, 29451, 29426, 29412, 29411, 29329, 29284, 29246, 29244, 29235, 29234, 29172, 29170, 29156, 29154, 29148, 29105, 29102, 29089, 29084, 29063, 29048, 29014, 28988, 28979, 28962, 28959, 28896, 28893, 28884, 28868, 28851, 28842, 28830, 28794, 28794, 28738, 28731, 28685, 28673, 28670, 28668, 28655, 28635, 28573, 28550, 28535, 28503, 28484, 28467, 28437, 28411, 28368, 28344, 28330, 28308, 28284, 28267, 28245, 28173, 28155, 28107, 28089, 28060, 28039, 28021, 28000, 27998, 27996, 27943, 27938, 27890, 27889, 27881, 27875, 27868, 27824, 27800, 27793, 27776, 27762, 27720, 27719, 27687, 27667, 27616, 27556, 27549, 27537, 27484, 27476, 27417, 27375, 27351, 27319, 27258, 27257, 27229, 27224, 27186, 27151, 27139, 27134, 27121, 27021, 27002, 26990, 26964, 26953, 26951, 26949, 26934, 26922, 26904, 26892, 26886, 26884, 26865, 26852, 26839, 26832, 26816, 26815, 26808, 26783, 26771, 26739, 26732, 26723, 26722, 26720, 26715, 26671, 26665, 26643, 26634, 26602, 26566, 26549, 26539, 26536, 26524, 26493, 26354, 26328, 26318, 26314, 26290, 26263, 26263, 26237, 26237, 26182, 26179, 26164, 26142, 26133, 26102, 26102, 26101, 26088, 26023, 26015, 26009, 25993, 25991, 25988, 25956, 25949, 25905, 25904, 25896, 25884, 25873, 25867, 25867, 25866, 25846, 25833, 25828, 25817, 25784, 25759, 25755, 25732, 25730, 25711, 25704, 25699, 25698, 25691, 25691, 25660, 25645, 25638, 25603, 25591, 25572, 25561, 25560, 25534, 25511, 25504, 25458, 25446, 25428, 25399, 25371, 25362, 25332, 25320, 25313, 25265, 25235, 25225, 25209, 25209, 25199, 25193, 25192, 25172, 25154, 25153, 25151, 25149, 25117, 25095, 25095, 25057, 25037, 25033, 24993, 24977, 24974, 24953, 24932, 24927, 24882, 24876, 24860, 24845, 24843, 24792, 24792, 24762, 24743, 24720, 24713, 24701, 24652, 24635, 24613, 24587, 24565, 24546, 24464, 24463, 24409, 24400, 24399, 24390, 24380, 24378, 24299, 24282, 24264, 24252, 24204, 24198, 24198, 24196, 24181, 24165, 24149, 24144, 24143, 24128, 24093, 24056, 24021, 24001, 23997, 23990, 23987, 23951, 23940, 23914, 23907, 23883, 23869, 23855, 23840, 23829, 23815, 23810, 23777, 23773, 23767, 23759, 23737, 23721, 23711, 23677, 23668, 23663, 23658, 23641, 23641, 23638, 23633, 23630, 23611, 23600, 23595, 23568, 23556, 23554, 23538, 23533, 23519, 23506, 23477, 23473, 23380, 23360, 23325, 23316, 23268, 23256, 23250, 23239, 23221, 23213, 23212, 23212, 23190, 23181, 23126, 23106, 23082, 23070, 23054, 23052, 23021, 23020, 23017, 22992, 22967, 22943, 22934, 22913, 22894, 22877, 22874, 22848, 22845, 22840, 22838, 22831, 22820, 22802, 22784, 22774, 22768, 22706, 22694, 22669, 22665, 22665, 22647, 22637, 22633, 22594, 22503, 22480, 22430, 22430, 22419, 22414, 22411, 22399, 22398, 22382, 22330, 22322, 22319, 22313, 22311, 22308, 22307, 22306, 22291, 22271, 22265, 22263, 22248, 22231, 22228, 22206, 22166, 22164, 22153, 22128, 22127, 22109, 22074, 22047, 22042, 22019, 22011, 21992, 21964, 21960, 21895, 21891, 21878, 21842, 21832, 21797, 21773, 21761, 21727, 21725, 21724, 21707, 21703, 21684, 21676, 21653, 21644, 21619, 21615, 21607, 21596, 21593, 21540, 21504, 21492, 21468, 21464, 21456, 21404, 21390, 21383, 21376, 21373, 21367, 21357, 21316, 21312, 21285, 21283, 21267, 21246, 21223, 21188, 21175, 21162, 21153, 21128, 21063, 21055, 21045, 21042, 21040, 21039, 21029, 21018, 20996, 20989, 20985, 20983, 20981, 20974, 20945, 20942, 20936, 20912, 20905, 20896, 20896, 20895, 20881, 20857, 20845, 20839, 20834, 20832, 20818, 20811, 20749, 20746, 20744, 20733, 20730, 20730, 20716, 20707, 20699, 20687, 20673, 20669, 20655, 20643, 20626, 20622, 20597, 20593, 20548, 20541, 20517, 20514, 20514, 20511, 20506, 20455, 20445, 20436, 20425, 20419, 20392, 20371, 20364, 20344, 20343, 20331, 20320, 20312, 20311, 20311, 20308, 20296, 20295, 20295, 20286, 20263, 20256, 20251, 20225, 20223, 20216, 20211, 20209, 20199, 20192, 20189, 20173, 20169, 20166, 20145, 20125, 20110, 20101, 20095, 20089, 20065, 20056, 20041, 20038, 20018, 20013, 19979, 19977, 19975, 19968, 19920, 19914, 19910, 19884, 19873, 19851, 19847, 19842, 19837, 19835, 19835, 19807, 19800, 19792, 19778, 19775, 19774, 19756, 19732, 19726, 19721, 19698, 19691, 19680, 19672, 19635, 19630, 19627, 19626, 19586, 19568, 19558, 19555, 19543, 19539, 19528, 19511, 19510, 19503, 19502, 19498, 19496, 19489, 19464, 19424, 19414, 19404, 19404, 19379, 19378, 19365, 19355, 19349, 19334, 19330, 19305, 19290, 19269, 19259, 19248, 19234, 19222, 19217, 19206, 19205, 19203, 19191, 19168, 19152, 19146, 19139, 19123, 19119, 19117, 19117, 19113, 19104, 19104, 19099, 19074, 19072, 19051, 19038, 19033, 19032, 19005, 18979, 18969, 18966, 18957, 18948, 18940, 18901, 18888, 18884, 18882, 18860, 18829, 18822, 18813, 18803, 18803, 18798, 18782, 18749, 18739, 18718, 18703, 18697, 18688, 18665, 18652, 18631, 18626, 18622, 18621, 18616, 18609, 18607, 18596, 18572, 18563, 18559, 18535, 18530, 18497, 18489, 18468, 18462, 18449, 18430, 18428, 18410, 18397, 18391, 18379, 18374, 18373, 18370, 18369, 18358, 18354, 18339, 18326, 18286, 18281, 18280, 18267, 18257, 18235, 18235, 18234, 18231, 18225, 18223, 18218, 18210, 18195, 18158, 18137, 18136, 18134, 18059, 18053, 18051, 18002, 17997, 17989, 17961, 17947, 17947, 17929, 17921, 17920, 17918, 17895, 17881, 17878, 17858, 17842, 17787, 17763, 17702, 17699, 17680, 17672, 17669, 17661, 17657, 17650, 17644, 17642, 17638, 17637, 17629, 17603, 17580, 17580, 17557, 17542, 17539, 17502, 17489, 17479, 17435, 17434, 17417, 17369, 17353, 17351, 17350, 17349, 17345, 17343, 17336, 17333, 17322, 17316, 17314, 17300, 17288, 17276, 17265, 17263, 17258, 17247, 17226, 17201, 17183, 17183, 17179, 17170, 17162, 17101, 17089, 17081, 17069, 17069, 17051, 17039, 17032, 17028, 17024, 17017, 17010, 17005, 16992, 16983, 16953, 16944, 16939, 16937, 16905, 16885, 16885, 16883, 16862, 16846, 16834, 16820, 16804, 16795, 16782, 16756, 16756, 16708, 16706, 16697, 16684, 16641, 16627, 16626, 16589, 16582, 16580, 16572, 16572, 16549, 16540, 16527, 16510, 16500, 16496, 16476, 16468, 16451, 16435, 16430, 16421, 16412, 16402, 16378, 16376, 16376, 16370, 16355, 16351, 16348, 16348, 16321, 16302, 16298, 16257, 16241, 16185, 16169, 16162, 16150, 16148, 16133, 16131, 16128, 16127, 16117, 16105, 16084, 16074, 16067, 16037, 16019, 16014, 15998, 15993, 15990, 15958, 15949, 15928, 15910, 15909, 15899, 15889, 15883, 15873, 15864, 15853, 15853, 15843, 15839, 15800, 15785, 15774, 15769, 15761, 15752, 15751, 15749, 15725, 15724, 15709, 15702, 15702, 15696, 15693, 15684, 15666, 15636, 15636, 15633, 15628, 15617, 15605, 15590, 15538, 15533, 15503, 15498, 15497, 15496, 15493, 15479, 15470, 15464, 15461, 15454, 15433, 15426, 15423, 15414, 15352, 15345, 15344, 15330, 15326, 15299, 15298, 15291, 15291, 15287, 15254, 15252, 15244, 15242, 15239, 15239, 15237, 15228, 15188, 15187, 15186, 15183, 15180, 15171, 15167, 15160, 15144, 15143, 15131, 15119, 15107, 15099, 15082, 15078, 15077, 15053, 15017, 15010, 15006, 14967, 14961, 14952, 14940, 14939, 14924, 14905, 14905, 14903, 14883, 14879, 14873, 14870, 14867, 14862, 14845, 14824, 14807, 14795, 14786, 14766, 14760, 14725, 14674, 14666, 14643, 14641, 14629, 14594, 14581, 14579, 14547, 14544, 14544, 14521, 14516, 14514, 14510, 14501, 14498, 14486, 14486, 14476, 14471, 14464, 14451, 14431, 14431, 14428, 14406, 14405, 14390, 14373, 14363, 14315, 14302, 14298, 14291, 14276, 14275, 14274, 14261, 14258, 14247, 14212, 14103, 14103, 14100, 14088, 14014, 13977, 13937, 13935, 13928, 13910, 13902, 13874, 13867, 13819, 13811, 13797, 13783, 13746, 13700, 13649, 13638, 13629, 13625, 13605, 13561, 13551, 13549, 13525, 13518, 13512, 13501, 13470, 13446, 13446, 13434, 13413, 13389, 13381, 13355, 13344, 13315, 13312, 13274, 13248, 13193, 13190, 13183, 13178, 13172, 13172, 13161, 13152, 13151, 13136, 13126, 13090, 13056, 12940, 12937, 12909, 12886, 12836, 12787, 12784, 12781, 12700, 12647, 12645, 12642, 12611, 12609, 12585, 12536, 12487, 12462, 12435, 12409, 12401, 12389, 12352, 12318, 12301, 12085, 12078, 12062, 12024, 12023, 12008, 12002, 11998, 11909, 11865, 11833, 11824, 11801, 11786, 11760, 11754, 11754, 11734, 11703, 11650, 11648, 11595, 11530, 11490, 11450, 11426, 11398, 11397, 11367, 11280, 11070, 10991, 10972, 10787, 10712, 10639, 10607, 10596, 10593, 10582, 10479, 10376, 10320, 10295, 10115, 9951, 9921, 9889, 9888, 9829, 9708, 9687, 9677, 9655, 9591, 9557, 9532, 9505, 9474, 9454, 9388, 9342, 9298, 9279, 9250, 9247, 9237, 9217, 9195, 9128, 9039, 9026, 8983, 8962, 8897, 8894, 8869, 8844, 8829, 8769, 8764, 8756, 8705, 8586, 8579, 8548, 8528, 8524, 8502, 8439, 8387, 8320, 8265, 8252, 8238, 8226, 8159, 8148, 8138, 8110, 8108, 8060, 8049, 8044, 8012, 8003, 7936, 7914, 7912, 7907, 7782, 7772, 7747, 7694, 7680, 7608, 7594, 7579, 7550, 7528, 7494, 7470, 7400, 7359, 7353, 7318, 7277, 7274, 7245, 7223, 7212, 7198, 7176, 7096, 7065, 7012, 6990, 6976, 6919, 6904, 6900, 6811, 6763, 6753, 6713, 6707, 6680, 6642, 6616, 6586, 6566, 6526, 6509, 6495, 6488, 6488, 6436, 6416, 6343, 6311, 6298, 6271, 6253, 6180, 6129, 6114, 6096, 6087, 6086, 6042, 5990, 5967, 5950, 5927, 5908, 5892, 5860, 5860, 5855, 5804, 5800, 5773, 5725, 5703, 5695, 5693, 5692, 5690, 5609, 5592, 5575, 5573, 5565, 5562, 5542, 5502, 5480, 5441, 5441, 5429, 5424, 5403, 5398, 5355, 5348, 5335, 5330, 5321, 5304, 5302, 5288, 5247, 5233, 5230, 5228, 5223, 5207, 5193, 5176, 5175, 5140, 5126, 5115, 5113, 5110, 5099, 5098, 5097, 5091, 5068, 5062, 5054, 5048, 5046, 5030, 5020, 5017, 5011, 4982, 4967, 4967, 4961, 4923, 4912, 4904, 4900, 4853, 4826, 4802, 4790, 4785, 4768, 4765, 4760, 4736, 4735, 4696, 4688, 4674, 4671, 4671, 4664, 4636, 4624, 4624, 4599, 4597, 4591, 4584, 4563, 4533, 4519, 4518, 4516, 4458, 4445, 4430, 4424, 4392, 4384, 4365, 4348, 4326, 4321, 4320, 4319, 4314, 4301, 4289, 4286, 4284, 4283, 4277, 4270, 4256, 4249, 4249, 4227, 4223, 4219, 4219, 4201, 4199, 4192, 4170, 4164, 4162, 4146, 4121, 4107, 4098, 4096, 4078, 4076, 4061, 4050, 4031, 4029, 4023, 4020, 4018, 3994, 3974, 3961, 3937, 3931, 3931, 3929, 3920, 3912, 3905, 3896, 3884, 3880, 3878, 3873, 3860, 3856, 3844, 3833, 3821, 3790, 3788, 3768, 3758, 3723, 3723, 3714, 3700, 3694, 3691, 3676, 3659, 3658, 3643, 3640, 3639, 3635, 3633, 3610, 3609, 3608, 3607, 3603, 3595, 3572, 3565, 3557, 3551, 3531, 3527, 3525, 3509, 3502, 3477, 3477, 3471, 3471, 3469, 3468, 3461, 3459, 3442, 3435, 3435, 3425, 3424, 3414, 3414, 3410, 3408, 3406, 3391, 3372, 3369, 3361, 3360, 3341, 3323, 3314, 3306, 3302, 3295, 3292, 3291, 3290, 3287, 3287, 3257, 3249, 3244, 3242, 3233, 3231, 3224, 3218, 3216, 3213, 3182, 3180, 3176, 3171, 3157, 3156, 3154, 3150, 3147, 3146, 3143, 3135, 3131, 3128, 3127, 3121, 3119, 3112, 3100, 3098, 3088, 3087, 3087, 3078, 3078, 3067, 3067, 3065, 3064, 3061, 3059, 3058, 3051, 3049, 3044, 3035, 3012, 3011, 2999, 2997, 2993, 2992, 2986, 2980, 2977, 2975, 2968, 2952, 2943, 2937, 2936, 2935, 2932, 2925, 2917, 2917, 2904, 2899, 2884, 2884, 2883, 2872, 2863, 2845, 2837, 2834, 2827, 2814, 2799, 2798, 2766, 2764, 2759, 2756, 2744, 2729, 2728, 2726, 2720, 2719, 2718, 2715, 2710, 2707, 2707, 2703, 2701, 2698, 2698, 2689, 2681, 2681, 2680, 2679, 2670, 2670, 2661, 2654, 2652, 2650, 2649, 2647, 2644, 2635, 2632, 2624, 2623, 2610, 2609, 2606, 2604, 2596, 2594, 2587, 2582, 2579, 2576, 2572, 2572, 2563, 2559, 2550, 2549, 2543, 2541, 2540, 2534, 2515, 2513, 2500, 2497, 2496, 2474, 2468, 2468, 2465, 2463, 2460, 2456, 2456, 2452, 2450, 2444, 2444, 2443, 2428, 2419, 2417, 2415, 2406, 2404, 2402, 2398, 2388, 2383, 2374, 2372, 2372, 2367, 2366, 2349, 2345, 2343, 2339, 2337, 2337, 2334, 2334, 2322, 2319, 2316, 2309, 2303, 2301, 2299, 2296, 2294, 2282, 2278, 2278, 2275, 2268, 2266, 2255, 2245, 2243, 2240, 2228, 2221, 2215, 2204, 2203, 2203, 2189, 2186, 2183, 2178, 2177, 2176, 2161, 2154, 2151, 2142, 2135, 2132, 2125, 2121, 2086, 2049, 2049, 2037, 2035, 2034, 2004, 2003, 2001, 1994, 1984, 1964, 1962, 1939, 1929, 1917, 1916, 1910, 1901, 1882, 1881, 1870, 1860, 1860, 1854, 1852, 1852, 1831, 1821, 1789, 1746, 1739, 1703, 1681, 1673, 1658, 1653, 1634, 1589, 1578, 1548, 1542, 1508, 1492, 1472, 1439, 1414, 1326, 1324, 1320, 1308, 1288]
19. Sắp xếp theo tần suất xuất hiện
Đưa ra tần suất xuất hiện của các giá trị trong cột 1; sắp xếp các giá trị trong cột 1 theo thứ tự từ cao đến thấp của tần suất xuất hiện. Xác nhận lại kết quả bằng việc dùng các lệnh cut, uniq, sort.
def frequency(input_file):
ret = {}
with open(input_file, 'r') as f:
for row in f:
l = row.strip().split('\t')
if l[0] in ret:
ret[l[0]] += 1
else:
ret[l[0]] = 1
print(sorted(ret.items(), key=lambda x:x[1], reverse=True))
input_file = 'popular-names.txt'
frequency(input_file)
[('James', 118), ('William', 111), ('John', 108), ('Robert', 108), ('Mary', 92), ('Charles', 75), ('Michael', 74), ('Elizabeth', 73), ('Joseph', 70), ('Margaret', 60), ('George', 58), ('Thomas', 58), ('David', 57), ('Richard', 51), ('Helen', 45), ('Frank', 43), ('Christopher', 43), ('Anna', 41), ('Edward', 40), ('Ruth', 39), ('Patricia', 38), ('Matthew', 37), ('Dorothy', 36), ('Emma', 35), ('Barbara', 32), ('Daniel', 31), ('Joshua', 31), ('Sarah', 26), ('Linda', 26), ('Jennifer', 26), ('Emily', 26), ('Jessica', 25), ('Jacob', 25), ('Mildred', 24), ('Betty', 24), ('Susan', 24), ('Henry', 23), ('Ashley', 23), ('Nancy', 22), ('Andrew', 21), ('Florence', 20), ('Marie', 20), ('Donald', 20), ('Amanda', 20), ('Samantha', 19), ('Karen', 18), ('Lisa', 18), ('Melissa', 18), ('Madison', 18), ('Olivia', 18), ('Stephanie', 17), ('Abigail', 17), ('Ethel', 16), ('Sandra', 16), ('Mark', 16), ('Frances', 15), ('Carol', 15), ('Angela', 15), ('Michelle', 15), ('Heather', 15), ('Ethan', 15), ('Isabella', 15), ('Shirley', 14), ('Kimberly', 14), ('Amy', 14), ('Ava', 14), ('Virginia', 13), ('Deborah', 13), ('Brian', 13), ('Jason', 13), ('Nicole', 13), ('Hannah', 13), ('Sophia', 13), ('Minnie', 12), ('Bertha', 12), ('Donna', 12), ('Cynthia', 11), ('Alice', 10), ('Doris', 10), ('Ronald', 10), ('Brittany', 10), ('Nicholas', 10), ('Mia', 10), ('Noah', 10), ('Joan', 9), ('Debra', 9), ('Tyler', 9), ('Ida', 8), ('Clara', 8), ('Judith', 8), ('Taylor', 8), ('Alexis', 8), ('Alexander', 8), ('Mason', 8), ('Harry', 7), ('Sharon', 7), ('Steven', 7), ('Tammy', 7), ('Brandon', 7), ('Liam', 7), ('Anthony', 6), ('Annie', 5), ('Gary', 5), ('Jeffrey', 5), ('Jayden', 5), ('Charlotte', 5), ('Lillian', 4), ('Kathleen', 4), ('Justin', 4), ('Austin', 4), ('Chloe', 4), ('Benjamin', 4), ('Evelyn', 3), ('Megan', 3), ('Aiden', 3), ('Harper', 3), ('Elijah', 3), ('Bessie', 2), ('Larry', 2), ('Rebecca', 2), ('Lauren', 2), ('Amelia', 2), ('Logan', 2), ('Oliver', 2), ('Walter', 1), ('Carolyn', 1), ('Pamela', 1), ('Lori', 1), ('Laura', 1), ('Tracy', 1), ('Julie', 1), ('Scott', 1), ('Kelly', 1), ('Crystal', 1), ('Rachel', 1), ('Lucas', 1)]
Chương 3: Biểu thức chính quy (Regular Expressions)

Tệp enwiki-country.json.gz lưu trữ các bài viết Wikipedia ở định dạng:
- Mỗi dòng lưu trữ một bài viết Wikipedia ở định dạng JSON.
- Mỗi tài liệu JSON có các cặp khóa-giá trị:
- Tiêu đề của bài viết là giá trị ứng với khóa "title".
- Phần nội dung của bài viết là giá trị ứng với khóa "text".
- Toàn bộ tập tin được nén bởi gzip.
Viết mã thực hiện các công việc sau.
!wget https://nlp100.github.io/data/enwiki-country.json.gz
20. Đọc vào dữ liệu JSON
Đọc các tài liệu JSON, trích xuất và hiển thị nội dung của bài viết về United Kingdom. Sử dụng các nội dung của tài liệu được trích xuất này để thực hiện các nhiệm vụ trong các bài tập từ 21-29.
import pandas as pd
input_file = 'enwiki-country.json.gz'
df = pd.read_json(input_file, lines=True)
ukText = df.query('title=="United Kingdom"')['text'].values[0]
print(ukText)
21. Trích xuất các dòng có chứa tên đề mục
Trong các tài liệu, trích xuất các dòng có chứa tên đề mục (category name).
import json
ukTextList = ukText.split('\n')
for data in ukTextList:
if '[[Category:' in data:
print(data)
22. Trích xuất các tên đề mục
Trích xuất tên đề mục của trong các tài liệu. Trong bài tập này, cần trích xuất chính xác các tên đề mục chứ không phải dòng chứa tên đề mục.
ukTextList = ukText.split('\n')
for data in ukTextList:
if '[[Category:' in data:
data = data.replace('[[Category:', '').replace('|*', '').replace(']]', '')
print(data)
23. Cấu trúc của các Section
Hiển thị tên của các section và level của các section trong các tài liệu Wikipedia (Ví dụ với section == Section Name ==" thì level bằng 1)
import re
repatter = re.compile("^[=+]")
for text in ukTextList:
if re.match(repatter, text):
print(int((len(text) - len(text.strip('='))) / 2 -1), text.strip('='))
24. Trích xuất các liên kết file
Trích xuất toàn bộ các liên kết đến các media files trong tài liệu.
import re
repatter = re.compile("\[\[*(file|ファイル)")
for text in ukTextList:
mache = re.search(repatter, text)
if mache:
print(re.split(r'[\||\]]', text[mache.span()[1]+1:])[0])
25. Infobox
Trích xuất tên trường và giá trị của chúng trong Infobox "country" và lưu trữ chúng trong một đối tượng từ điển (dictionary).
def ch025():
ls, fg = [], False
template = 'Infobox'
p1 = re.compile('\{\{' + template)
p2 = re.compile('\}\}')
p3 = re.compile('\|')
p4 = re.compile('<ref(\s|>).+?(</ref>|$)')
for l in ukText.split('\n'):
if fg:
ml = [p2.match(l), p3.match(l)]
if ml[0]:
break
if ml[1]:
ls.append(p4.sub('', l.strip()))
if p1.match(l):
fg = True
ret = {}
for l in ls:
d = l.strip('|').split('=')
ret[d[0]] = d[1]
return ret
from pprint import pprint
pprint(ch025())
26. Loại bỏ các emphasis markups
Trong khi làm các xử lý ở bài tập 25, xoá các MediaWiki emphasis markup (italic, bold, both) trong giá trị của các trường và biến đổi thành plain text. Xem thêm tại Help:Cheatsheet.
def remove_stress(basic_information):
r = re.compile("''+")
return {k: r.sub('', v) for k, v in basic_information.items()}
ch26 = remove_stress(ch025())
27. Xóa bỏ các Internal Links
Bên cạnh những xử lý trong bài tập 26, hãy xóa những liên kết trong từ các giá trị của các trường. Xem thêm tại Help:Cheatsheet.
def remove_inner_links(basic_information):
pattern = re.compile('\[\[.+\]\]')
for k, v in basic_information.items():
#print(v)
text = v.strip()
if re.match(pattern, text):
l = re.sub('\[\[|\]\]', '', text).split('|')
if ':' not in l [0]:
basic_information[k] = l[0]
return basic_information
ch27 = remove_inner_links(ch26)
28. Xoá các markup trong văn bản
Ngoài các xử lý ở bài 27, hãy xoá các Media markup trong các giá trị của các trường ở Infobox càng nhiều càng tốt và in ra các thông tin cơ bản về quốc gia ở dạng plaintext.
import re
def remove_file_link(text):
r = re.compile(u'^\[\[(?:ファイル|File):(?P<name>.+?)\|.+')
return r.sub('\g<name>', text)
def remove_lang(text):
r = re.compile(u'{{lang\|.+\|(?P<name>.+?)}}')
return r.sub('\g<name>', text)
def remove_external_link(text):
r = re.compile(r'\['
r'(?P<url>\S+)'
r'\s?'
r'(?P<name>.+?)?'
r'\]')
m = r.search(text)
if m is None:
return text
if m.group('name'):
return m.group('name')
return m.group('url')
data = load_data()
info = extract_basic_info(data)
for key, val in info.items():
print('key = {}'.format(key.encode('utf8')))
val = remove_emphasis(val)
val = remove_internal_link(val)
val = remove_external_link(val)
val = remove_file_link(val)
val = remove_lang(val)
print('value = {}\n'.format(val.encode('utf8')))
29. Lấy ra các URL của quốc kỳ
Lấy URL của quốc gia bằng cách sử dụng kết quả phân tích của Infobox. (Gợi ý: chuyển đổi tham chiếu file thành URL bằng cách gọi imageinfo trong MediaWiki API)
import requests
def get_url(basic_information):
url_file = basic_information['国旗画像 '].replace(' ', '_')
url = 'https://commons.wikimedia.org/w/api.php?action=query&titles=File:' + url_file + '&prop=imageinfo&iiprop=url&format=json'
data = requests.get(url)
return re.search(r'"url":"(.+?)"', data.text).group(1)
get_url(ch27)
'https://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svg'
Chương 4: Morphological Analysis trong tiếng Nhật (形態素解析)
Dùng MeCab để phân tích hình thái cho nội dung text của cuốn tiểu thuyết "Tôi là một con mèo" (neko.txt) tác giả Soseki Natsume, và lưu kết quả vào file neko.txt.mecab. Sử dụng file kết quả để thực hiện các công việc ở các bài tập dưới đây.
Đối với các bài tập 37, 38, 39, có thể sử dụng các phần mềm matplitlib hoặc Gnuplot.
!wget https://nlp100.github.io/data/neko.txt
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
30. Đọc vào kết quả morphological analysis
Viết chương trình đọc vào kết quả morphological analysis (file neko.txt.mecab).
Yêu cầu: Với mỗi morpheme, lưu các thông tin: 表層形 (surface form), 基本形 (base form), 品詞 (pos), 品詞細分類 1 (pos1) bằng cấu trúc dữ liệu hash map với các key tương ứng là: surface, base, pos, pos1. Lưu trữ mỗi câu bằng danh sách của các morpheme. Trong các bài tập còn lại trong chương 4, hãy sử dụng cách tổ chức dữ liệu trong bài này.
def parseMecab(block):
res = []
for line in block.split('\n'):
if line == '':
return res
(surface, attr) = line.split('\t')
attr = attr.split(',')
lineDict = {
'surface': surface,
'base': attr[6],
'pos': attr[0],
'pos1': attr[1]
}
res.append(lineDict)
filename = 'neko.txt.mecab'
with open(filename, mode='rt', encoding='utf-8') as f:
block_list = f.read().split('EOS\n')
block_list = list(filter(lambda x: x != '', block_list))
block_list = [parseMecab(block) for block in block_list]
for b in block_list[1]:
print(b)
31. Động từ
Trích xuất tất cả các surface forms của động từ (pos=動詞).
def extract(block, mode):
res = list(filter(lambda x: x['pos'] == '動詞', block))
res = [r[mode] for r in res]
return res
cnt = 0
for b in block_list:
ret = extract(b, mode='surface')
print(ret)
cnt += 1
if cnt >= 10:
break
[]
[]
[]
[]
[]
['生れ', 'つか']
['し', '泣い', 'し', 'いる']
['始め', '見']
['聞く']
['捕え', '煮', '食う']
32. Dạng nguyên thể của động từ (動詞の原形)
Trích xuất tất cả dạng nguyên thể của động từ (base form).
cnt = 0
for b in block_list:
ret = extract(b, mode='base')
print(ret)
cnt += 1
if cnt >= 10:
break
[]
[]
[]
[]
[]
['生れる', 'つく']
['する', '泣く', 'する', 'いる']
['始める', '見る']
['聞く']
['捕える', '煮る', '食う']
33.「A の B」
Trích xuất tất cả các danh từ ghép (compound nouns) gồm 2 danh từ kết nối bằng の.
def extract(block):
if len(block) <=3:
return
res = []
for i in range(1, len(block) - 1):
if block[i-1]['pos'] == '名詞' and block[i]['surface'] == 'の' and block[i+1]['pos'] == '名詞':
res.append([block[i-1], block[i], block[i+1]])
return res
cnt = 0
for b in block_list:
res = extract(b)
if res:
for noun_phrase in res:
print(noun_phrase[0]['surface'], noun_phrase[1]['surface'], noun_phrase[2]['surface'])
cnt += 1
if cnt >= 40:
break
彼 の 掌
掌 の 上
書生 の 顔
はず の 顔
顔 の 真中
穴 の 中
書生 の 掌
掌 の 裏
何 の 事
肝心 の 母親
藁 の 上
笹原 の 中
池 の 前
34. Trích xuất các kết nối danh từ (noun connections hay 名詞の連接)
Trích xuất tất cả các noun connections (các danh từ đứng cạnh nhau liên tiếp). Khi trích xuất, chú ý trích xuất chuỗi danh từ matching dài nhất có thể. Ví dụ ABC trong đó A, B, C là danh từ thì phải trích xuất ABC thay vì AB.
def extract(block):
res = []
res_candidate = []
for token in block:
if token['pos'] == '名詞':
res_candidate.append(token)
elif token['pos'] != '名詞' and len(res_candidate) >= 2:
print(res_candidate)
res.extend(res_candidate)
res_candidate.clear()
elif token['pos'] != '名詞' and len(res_candidate) < 2:
res_candidate.clear()
return res
cnt = 0
for b in block_list:
res = extract(b)
#print(res)
cnt += 1
if cnt >= 10:
break
[{'surface': '人間', 'base': '人間', 'pos': '名詞', 'pos1': '一般'}, {'surface': '中', 'base': '中', 'pos': '名詞', 'pos1': '接尾'}]
[{'surface': '一番', 'base': '一番', 'pos': '名詞', 'pos1': '副詞可能'}, {'surface': '獰悪', 'base': '獰悪', 'pos': '名詞', 'pos1': '形容動詞語幹'}]
35. Tần suất xuất hiện của từ
Lập trình tính tần suất xuất hiện của từ trong văn bản. Đưa ra các từ theo thứ tự giảm dần của tần suất xuất hiện.
def extract(block):
res = []
res_candidate = []
for token in block:
if token['pos'] == '名詞':
res_candidate.append(token)
elif token['pos'] != '名詞' and len(res_candidate) >= 2:
print(res_candidate)
res.extend(res_candidate)
res_candidate.clear()
elif token['pos'] != '名詞' and len(res_candidate) < 2:
res_candidate.clear()
return res
cnt = 0
for b in block_list:
res = extract(b)
#print(res)
cnt += 1
if cnt >= 10:
break
[{'surface': '人間', 'base': '人間', 'pos': '名詞', 'pos1': '一般'}, {'surface': '中', 'base': '中', 'pos': '名詞', 'pos1': '接尾'}]
[{'surface': '一番', 'base': '一番', 'pos': '名詞', 'pos1': '副詞可能'}, {'surface': '獰悪', 'base': '獰悪', 'pos': '名詞', 'pos1': '形容動詞語幹'}]
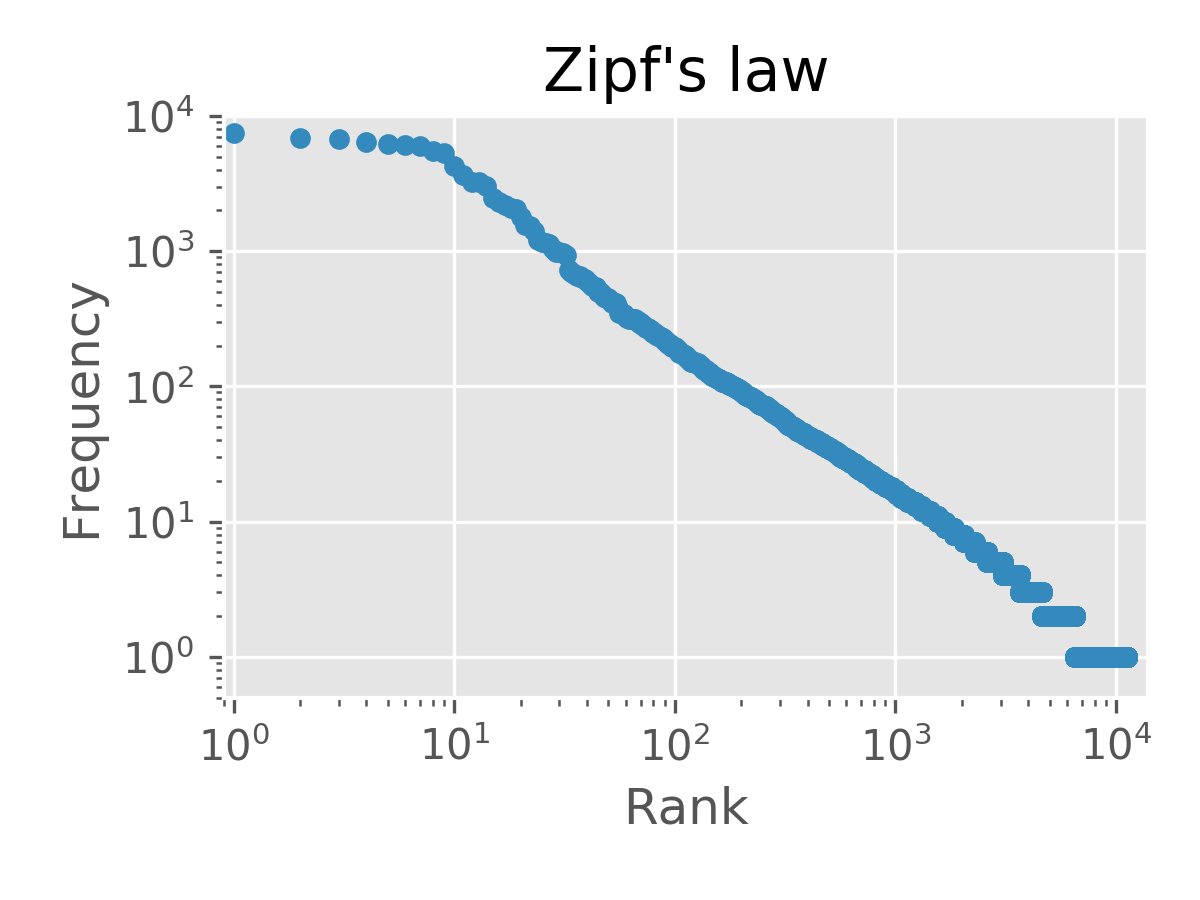
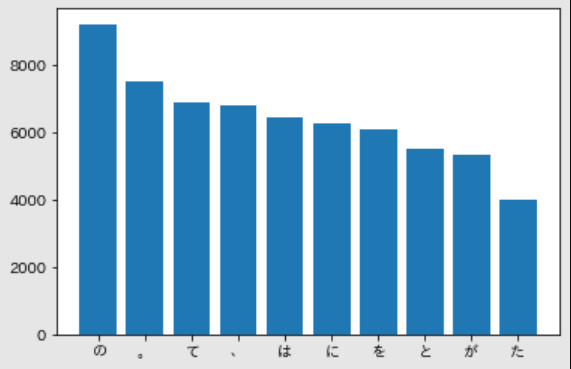
36. Top 10 từ xuất hiện nhiều nhất
Vẽ đồ thị (ví dụ bar graph) của tần suất xuất hiện của 10 từ xuất hiện nhiều nhất trong văn bản.
# Loại bỏ các ký tự tiếng Nhật bị cắt xén !
!pip install japanize-matplotlib
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
def plot_frequency_token(block_list, top=10):
res = {}
for block in block_list:
for token in block:
ts = token['surface']
if ts in res:
res[ts] += 1
else:
res[ts] = 1
#print(len(res))
frequency_top = sorted(res.items(), key=lambda x:-x[1])
#print(frequency_top[0][1])
left = np.array([i+1 for i in range(top)])
height = np.array([token[1] for token in frequency_top[:top]])
label = [token[0] for token in frequency_top[:top]]
plt.bar(left, height, tick_label=label, align="center")
plt.show()
plot_frequency_token(block_list)
37. Top 10 từ đồng xuất hiện với từ 猫
Vẽ đồ thị (ví dụ: bar plot) tần suất xuất hiện của top 10 từ đồng xuất hiện nhiều nhất với từ 猫.
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
def extract(block):
return [b['surface'] for b in block]
def plot_collocation(block_list, word, top=10):
res = {}
token_list = [extract(block) for block in block_list]
token_list = list(filter(lambda x: word in x, token_list))
for line in token_list:
for token in line:
if token != '猫':
if token in res:
res[token] += 1
else:
res[token] = 1
frequency_top = sorted(res.items(), key=lambda x:-x[1])
left = np.array([i+1 for i in range(top)])
height = np.array([token[1] for token in frequency_top[:top]])
label = [token[0] for token in frequency_top[:top]]
plt.bar(left, height, tick_label=label, align="center")
plt.show()
plot_collocation(block_list, word='猫')
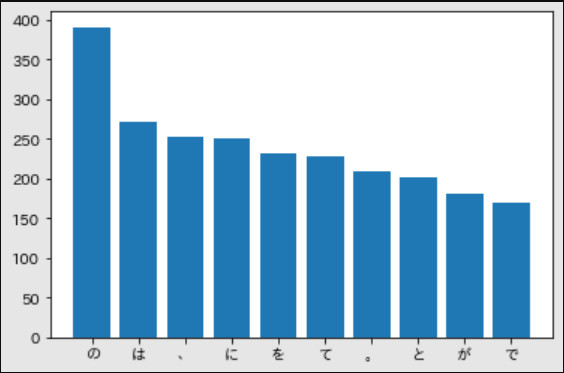
38. Histogram
Vẽ đồ thị histogram tần suất xuất hiện của các từ. Trục ngang là tần suất xuất hiện. Trục dọc là các từ.
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
def extract(block):
return [b['surface'] for b in block]
def plot_frequency_hist(block_list):
res = {}
token_list = [extract(block) for block in block_list]
for line in token_list:
for token in line:
if token in res:
res[token] += 1
else:
res[token] = 1
ans = res.values()
print(sorted(ans, reverse=False))
plt.figure(figsize=(8, 8))
plt.hist(ans, bins=100)
plt.show()
plot_frequency_hist(block_list)
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 34, 34, 34, 34, 34, 34, 34, 34, 34, 34, 34, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 35, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 39, 39, 39, 39, 39, 39, 39, 39, 39, 39, 39, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 42, 42, 42, 42, 42, 42, 42, 43, 43, 43, 43, 43, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 45, 45, 45, 45, 45, 45, 45, 45, 45, 45, 46, 46, 46, 46, 46, 46, 46, 47, 47, 47, 47, 47, 47, 47, 47, 48, 48, 48, 48, 48, 48, 48, 48, 49, 49, 49, 49, 49, 50, 50, 50, 51, 51, 51, 51, 51, 51, 51, 51, 52, 52, 52, 52, 52, 52, 52, 53, 53, 54, 55, 55, 55, 55, 55, 55, 55, 55, 56, 56, 56, 56, 56, 57, 57, 57, 57, 57, 57, 58, 58, 59, 59, 59, 60, 60, 60, 60, 60, 60, 61, 61, 61, 61, 62, 62, 62, 62, 62, 62, 62, 63, 63, 63, 63, 63, 63, 64, 64, 64, 65, 65, 65, 65, 65, 65, 65, 65, 65, 66, 66, 66, 67, 67, 67, 68, 68, 68, 70, 70, 70, 70, 71, 71, 71, 71, 71, 72, 72, 72, 72, 73, 73, 73, 73, 73, 73, 74, 74, 74, 74, 75, 75, 75, 76, 76, 77, 77, 78, 79, 79, 80, 80, 80, 81, 82, 82, 82, 83, 83, 84, 84, 84, 84, 84, 85, 85, 85, 86, 86, 86, 87, 87, 88, 88, 88, 89, 89, 89, 90, 90, 91, 92, 93, 93, 93, 93, 93, 94, 94, 95, 96, 97, 97, 97, 97, 98, 98, 99, 99, 100, 101, 101, 102, 103, 103, 103, 104, 104, 106, 106, 107, 107, 107, 108, 108, 109, 109, 109, 111, 111, 112, 113, 114, 114, 115, 116, 116, 116, 117, 118, 118, 119, 120, 121, 125, 125, 126, 127, 127, 131, 132, 133, 133, 134, 137, 138, 139, 140, 141, 142, 143, 143, 143, 144, 146, 146, 147, 148, 149, 149, 150, 150, 150, 150, 152, 153, 154, 154, 158, 159, 162, 169, 169, 172, 175, 175, 179, 181, 182, 185, 189, 194, 194, 194, 195, 195, 199, 205, 213, 216, 220, 221, 225, 231, 231, 232, 234, 238, 241, 244, 245, 246, 248, 249, 250, 258, 260, 262, 268, 269, 270, 272, 273, 274, 277, 282, 286, 289, 294, 299, 303, 312, 313, 313, 319, 319, 320, 330, 343, 345, 346, 350, 356, 364, 381, 404, 411, 414, 433, 448, 458, 478, 481, 483, 509, 514, 531, 539, 546, 554, 576, 602, 617, 636, 649, 683, 696, 932, 937, 973, 973, 981, 992, 992, 1034, 1207, 1249, 1530, 1568, 1613, 1728, 2032, 2322, 2363, 2390, 2479, 3225, 3231, 3806, 3988, 5337, 5508, 6071, 6243, 6420, 6772, 6868, 7486, 9194]
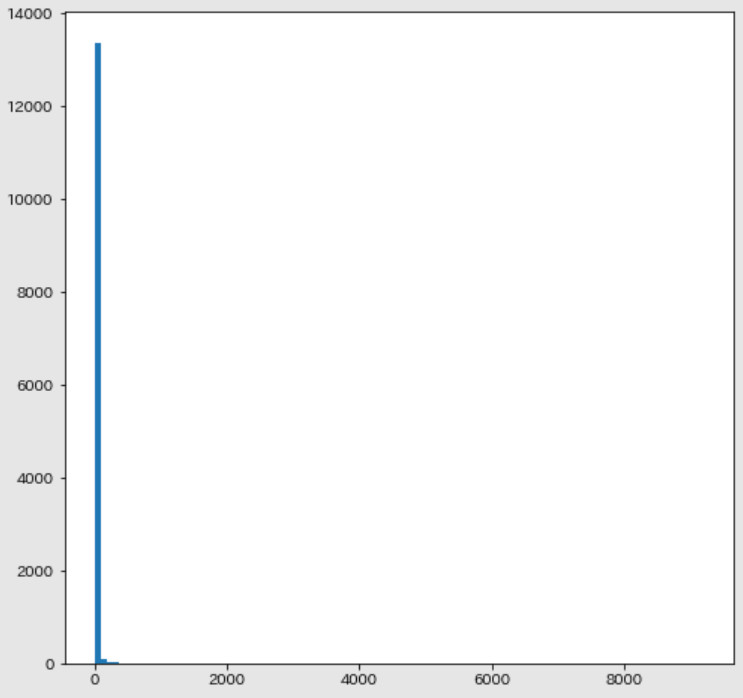
39. Luật Zipf
Vẽ đồ thị với trục ngang là rank của các từ theo tần suất xuất hiện (cao đến thấp), trục dọc là tần suất xuất hiện của các từ. Vẽ đồ thị log-log để thể hiện.
import math
def plot_zipf(block_list):
res = {}
token_list = [extract(block) for block in block_list]
for line in token_list:
for token in line:
if token in res:
res[token] += 1
else:
res[token] = 1
ans = sorted(res.items(), key=lambda x: x[1], reverse=True)
#print(sorted(ans, reverse=False))
ranks = [math.log(r + 1) for r in range(len(ans))]
values = [math.log(a[1]) for a in ans]
plt.figure(figsize=(8, 8))
plt.scatter(ranks, values)
plt.show()
plot_zipf(block_list)
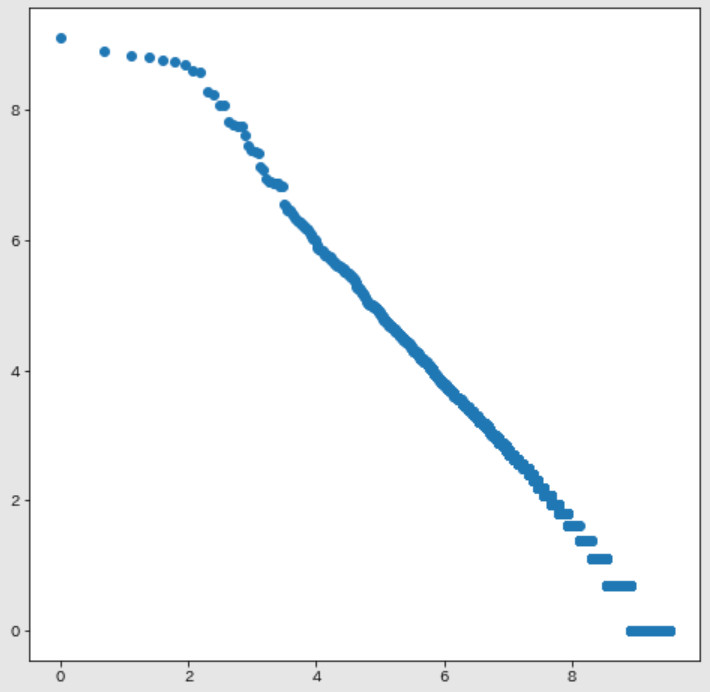
Chương 5: Dependency parsing (係り受け解析)
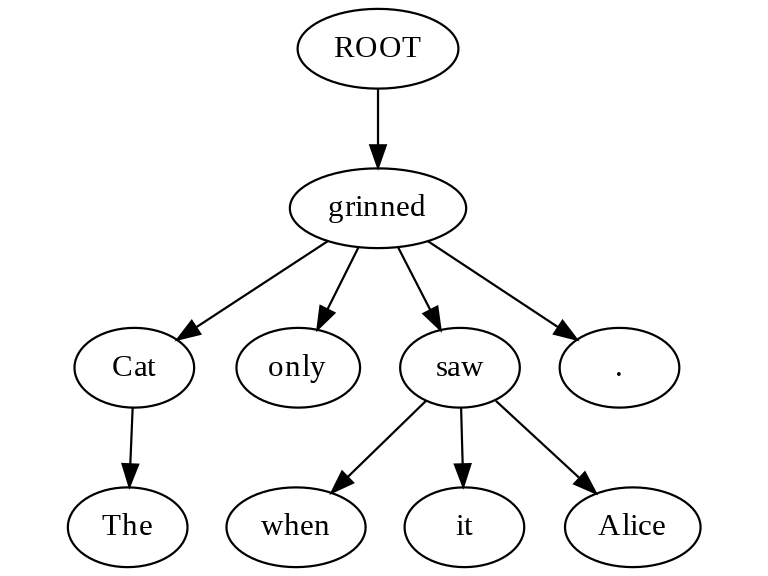
Thực hiện phân tích cấu trúc ngữ pháp (dependency parsing) bằng công cụ CaboCha cho file neko.txt và lưu kết quả vào file neko.txt.cabocha. Sử dụng file kết quả này làm đầu vào cho các bài tập dưới đây.
Cài đặt CaboCha
!apt install -y \
curl \
file \
git \
libmecab-dev \
make \
mecab \
mecab-ipadic-utf8 \
swig \
xz-utils
!pip install mecab-python3
import os
filename_crfpp = 'crfpp.tar.gz'
!wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" -O $filename_crfpp
!tar zxvf $filename_crfpp
%cd CRF++-0.58
!./configure
!make
!make install
%cd ..
os.environ['LD_LIBRARY_PATH'] += ':/usr/local/lib'
FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
FILE_NAME = "cabocha.tar.bz2"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
!tar -xvf cabocha.tar.bz2
%cd cabocha-0.69
!./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
!make
!make check
!make install
%cd ..
!cabocha --version
%cd cabocha-0.69/python
!python setup.py build_ext
!python setup.py install
!ldconfig
%cd ../..
!type cabocha
!cabocha --help
Cài đặt font chữ tiếng Nhật
!apt-get -y install fonts-ipafont-gothic
Cài đặt phần phụ thuộc
import numpy as np
from scipy.sparse.csgraph import shortest_path
import itertools
import pydot
from IPython.display import Image, display
from pprint import pprint
neko.txt.cabocha
!curl -fsSLO https://nlp100.github.io/data/neko.txt
!ls -l neko.txt
!cabocha -I0 -O4 -f1 -o neko.txt.cabocha neko.txt
!ls -l neko.txt.cabocha
-rw-r--r-- 1 root root 965825 Apr 22 13:24 neko.txt
-rw-r--r-- 1 root root 13208723 Apr 22 13:24 neko.txt.cabocha
!head -n 20 neko.txt.cabocha
* 0 -1D 0/0 0.000000
一 名詞,数,*,*,*,*,一,イチ,イチ
EOS
EOS
* 0 2D 0/0 -0.764522
記号,空白,*,*,*,*, , ,
* 1 2D 0/1 -0.764522
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 2 -1D 0/2 0.000000
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
EOS
* 0 2D 0/1 -1.911675
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 1 2D 0/0 -1.911675
まだ 副詞,助詞類接続,*,*,*,*,まだ,マダ,マダ
40. Đọc vào kết quả dependency parsing (theo morphemes)
Cài đặt lớp Morph cho các morphemes. Lớp này có các biến thành phần (member variables) là surface (cho surface forms của morphems), base (cho base form), pos (cho POS tag), pos1 (cho detailed POS tag - 品詞細分類). Sau đó đọc vào kết quả phân tích dependency parsing trong file neko.txt.cabocha. Mỗi câu sẽ bao gồm một danh sách các Morph objects. Hiển thị danh sách các morphemes cho câu thứ 3 trong văn bản.
class Morph():
def __init__(self, line):
try:
lines = line.split('\t')
self.surface = lines[0]
lines = lines[1].split(',')
self.base = lines[6]
self.pos = lines[0]
self.pos1 = lines[1]
except Exception as e:
raise(e)
def __str__(self):
return 'Morph(surface: {}, base: {}, pos: {}, pos1: {})'.format(
self.surface, self.base, self.pos, self.pos1
)
def __repr__(self):
return self.__str__()
def surface_from(morphs):
return ''.join([m.surface for m in morphs])
def poss_from(morphs):
return [m.pos for m in morphs]
with open('neko.txt.cabocha', 'r') as f:
neko = f.readlines()
c = 0
morphs = []
for line in neko:
if line.startswith('* 0'):
c += 1
if c == 4:
if any([line.startswith(key) for key in ['*', 'EOS']]):
continue
try:
morphs.append(Morph(line))
except Exception as e:
print('Line: {}'.format(line))
print('Error: {}'.format(e))
if c > 4:
break
pprint(morphs)
[Morph(surface: , base: , pos: 記号, pos1: 空白),
Morph(surface: どこ, base: どこ, pos: 名詞, pos1: 代名詞),
Morph(surface: で, base: で, pos: 助詞, pos1: 格助詞),
Morph(surface: 生れ, base: 生れる, pos: 動詞, pos1: 自立),
Morph(surface: た, base: た, pos: 助動詞, pos1: *),
Morph(surface: か, base: か, pos: 助詞, pos1: 副助詞/並立助詞/終助詞),
Morph(surface: とんと, base: とんと, pos: 副詞, pos1: 一般),
Morph(surface: 見当, base: 見当, pos: 名詞, pos1: サ変接続),
Morph(surface: が, base: が, pos: 助詞, pos1: 格助詞),
Morph(surface: つか, base: つく, pos: 動詞, pos1: 自立),
Morph(surface: ぬ, base: ぬ, pos: 助動詞, pos1: *),
Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)]
41. Đọc vào kết quả dependency parsing (theo chunks và depedency relations)
Tiếp theo bài 40, cài đặt lớp Chunk để lưu trữ các chunk (hay bunsetsu (文節)). Lớp này có các biến thành phần là:
- morphs (để lưu trữ danh sách các Morph objects)
- dst để lưu trữ index của chunk mà chunk hiện tại trỏ đến (chunk đích - destination)
- srcs để lưu trữ danh sách các indexes của các chunk trỏ đến chunk hiện tại.
Sau đó, đọc vào kết quả dependency parsing. Mỗi câu sẽ bao gồm danh sách của các Chunk objects. Hiển thị nội dung text và giá trị của biến dst của các chunk trong câu thứ 8 của file đầu vào.
Các bài tập còn lại trong chương 5 sẽ sử dụng các chương trình được tạo ra ở đây.
class Chunk():
"""文節・係り受けを表すクラス"""
def __init__(self, lines):
self.morphs = []
self.id = 0
self.dst = -1
self.srcs = []
for line in lines:
if line.startswith('*'):
try:
self.id = line.split()[1]
self.dst = line.split()[2][:-1]
except Exception as e:
print('dst parse error')
print('Line: {}'.format(line))
print('Error: {}'.format(e))
else:
try:
self.morphs.append(Morph(line))
except Exception as e:
print('morph parse error')
print('Line: {}'.format(line))
print('Error: {}'.format(e))
def __str__(self):
return 'Chunk(id: {}, dst: {}, srcs: {}, morphs: {})'.format(
self.id, self.dst, self.srcs, self.morphs
)
def __repr__(self):
return self.__str__()
with open('neko.txt.cabocha', 'r') as f:
neko = f.readlines()
c = 0
chunks = []
morphs = []
for line in neko:
if line.startswith('* 0'):
c += 1
if c == 9:
if any([line.startswith(key) for key in ['EOS']]):
continue
if line.startswith('*'):
chunks.append(Chunk(morphs))
morphs = [line]
else:
morphs.append(line)
if c > 9:
chunks.append(Chunk(morphs))
break
for c in chunks:
c.srcs = [s.id for s in chunks if s.dst == c.id]
pprint(chunks[1:])
[Chunk(id: 0, dst: 9, srcs: [], morphs: [Morph(surface: しかし, base: しかし, pos: 接続詞, pos1: *)]),
Chunk(id: 1, dst: 2, srcs: [], morphs: [Morph(surface: その, base: その, pos: 連体詞, pos1: *)]),
Chunk(id: 2, dst: 5, srcs: ['1'], morphs: [Morph(surface: 当時, base: 当時, pos: 名詞, pos1: 副詞可能), Morph(surface: は, base: は, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 3, dst: 4, srcs: [], morphs: [Morph(surface: 何, base: 何, pos: 名詞, pos1: 代名詞), Morph(surface: という, base: という, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 4, dst: 5, srcs: ['3'], morphs: [Morph(surface: 考, base: 考, pos: 名詞, pos1: 一般), Morph(surface: も, base: も, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 5, dst: 9, srcs: ['2', '4'], morphs: [Morph(surface: なかっ, base: ない, pos: 形容詞, pos1: 自立), Morph(surface: た, base: た, pos: 助動詞, pos1: *), Morph(surface: から, base: から, pos: 助詞, pos1: 接続助詞)]),
Chunk(id: 6, dst: 7, srcs: [], morphs: [Morph(surface: 別段, base: 別段, pos: 副詞, pos1: 助詞類接続)]),
Chunk(id: 7, dst: 9, srcs: ['6'], morphs: [Morph(surface: 恐し, base: 恐い, pos: 形容詞, pos1: 自立)]),
Chunk(id: 8, dst: 9, srcs: [], morphs: [Morph(surface: いとも, base: いとも, pos: 副詞, pos1: 一般)]),
Chunk(id: 9, dst: -1, srcs: ['0', '5', '7', '8'], morphs: [Morph(surface: 思わ, base: 思う, pos: 動詞, pos1: 自立), Morph(surface: なかっ, base: ない, pos: 助動詞, pos1: *), Morph(surface: た, base: た, pos: 助動詞, pos1: *), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])]
42. Hiển thị chunk nguồn (head) và chunk đích (modifier) trong các depedency relations
Hiển thị nội dung dạng text các chunk nguồn (head) và chunk đích (modifier) trên mỗi dòng và cách nhau bởi ký tự tab. Chú ý không hiển thị các dấu (punctuation marks) trong các chunk.
with open('neko.txt.cabocha', 'r') as f:
neko = f.readlines()
book = []
chunks = []
morphs = []
for line in neko:
if any([line.startswith(key) for key in ['EOS']]):
continue
if line.startswith('*'):
chunks.append(Chunk(morphs))
if line.startswith('* 0'):
for c in chunks:
c.srcs = [s.id for s in chunks if s.dst == c.id]
book.append(chunks)
chunks = []
morphs = [line]
else:
morphs.append(line)
pprint(book[1:7])
[[Chunk(id: 0, dst: -1, srcs: [], morphs: [Morph(surface: 一, base: 一, pos: 名詞, pos1: 数)])],
[Chunk(id: 0, dst: 2, srcs: [], morphs: [Morph(surface: , base: , pos: 記号, pos1: 空白)]),
Chunk(id: 1, dst: 2, srcs: [], morphs: [Morph(surface: 吾輩, base: 吾輩, pos: 名詞, pos1: 代名詞), Morph(surface: は, base: は, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 2, dst: -1, srcs: ['0', '1'], morphs: [Morph(surface: 猫, base: 猫, pos: 名詞, pos1: 一般), Morph(surface: で, base: だ, pos: 助動詞, pos1: *), Morph(surface: ある, base: ある, pos: 助動詞, pos1: *), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])],
[Chunk(id: 0, dst: 2, srcs: [], morphs: [Morph(surface: 名前, base: 名前, pos: 名詞, pos1: 一般), Morph(surface: は, base: は, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 1, dst: 2, srcs: [], morphs: [Morph(surface: まだ, base: まだ, pos: 副詞, pos1: 助詞類接続)]),
Chunk(id: 2, dst: -1, srcs: ['0', '1'], morphs: [Morph(surface: 無い, base: 無い, pos: 形容詞, pos1: 自立), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])],
[Chunk(id: 0, dst: 1, srcs: [], morphs: [Morph(surface: , base: , pos: 記号, pos1: 空白), Morph(surface: どこ, base: どこ, pos: 名詞, pos1: 代名詞), Morph(surface: で, base: で, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 1, dst: 4, srcs: ['0'], morphs: [Morph(surface: 生れ, base: 生れる, pos: 動詞, pos1: 自立), Morph(surface: た, base: た, pos: 助動詞, pos1: *), Morph(surface: か, base: か, pos: 助詞, pos1: 副助詞/並立助詞/終助詞)]),
Chunk(id: 2, dst: 4, srcs: [], morphs: [Morph(surface: とんと, base: とんと, pos: 副詞, pos1: 一般)]),
Chunk(id: 3, dst: 4, srcs: [], morphs: [Morph(surface: 見当, base: 見当, pos: 名詞, pos1: サ変接続), Morph(surface: が, base: が, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 4, dst: -1, srcs: ['1', '2', '3'], morphs: [Morph(surface: つか, base: つく, pos: 動詞, pos1: 自立), Morph(surface: ぬ, base: ぬ, pos: 助動詞, pos1: *), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])],
[Chunk(id: 0, dst: 1, srcs: [], morphs: [Morph(surface: 何, base: 何, pos: 名詞, pos1: 代名詞), Morph(surface: でも, base: でも, pos: 助詞, pos1: 副助詞)]),
Chunk(id: 1, dst: 3, srcs: ['0'], morphs: [Morph(surface: 薄暗い, base: 薄暗い, pos: 形容詞, pos1: 自立)]),
Chunk(id: 2, dst: 3, srcs: [], morphs: [Morph(surface: じめじめ, base: じめじめ, pos: 副詞, pos1: 一般), Morph(surface: し, base: する, pos: 動詞, pos1: 自立), Morph(surface: た, base: た, pos: 助動詞, pos1: *)]),
Chunk(id: 3, dst: 5, srcs: ['1', '2'], morphs: [Morph(surface: 所, base: 所, pos: 名詞, pos1: 非自立), Morph(surface: で, base: で, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 4, dst: 5, srcs: [], morphs: [Morph(surface: ニャーニャー, base: *
, pos: 名詞, pos1: 一般)]),
Chunk(id: 5, dst: 7, srcs: ['3', '4'], morphs: [Morph(surface: 泣い, base: 泣く, pos: 動詞, pos1: 自立), Morph(surface: て, base: て, pos: 助詞, pos1: 接続助詞)]),
Chunk(id: 6, dst: 7, srcs: [], morphs: [Morph(surface: いた事, base: いた事, pos: 名詞, pos1: 一般), Morph(surface: だけ, base: だけ, pos: 助詞, pos1: 副助詞), Morph(surface: は, base: は, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 7, dst: -1, srcs: ['5', '6'], morphs: [Morph(surface: 記憶, base: 記憶, pos: 名詞, pos1: サ変接続), Morph(surface: し, base: する, pos: 動詞, pos1: 自立), Morph(surface: て, base: て, pos: 助詞, pos1: 接続助詞), Morph(surface: いる, base: いる, pos: 動詞, pos1: 非自立), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])],
[Chunk(id: 0, dst: 5, srcs: [], morphs: [Morph(surface: 吾輩, base: 吾輩, pos: 名詞, pos1: 代名詞), Morph(surface: は, base: は, pos: 助詞, pos1: 係助詞)]),
Chunk(id: 1, dst: 2, srcs: [], morphs: [Morph(surface: ここ, base: ここ, pos: 名詞, pos1: 代名詞), Morph(surface: で, base: で, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 2, dst: 3, srcs: ['1'], morphs: [Morph(surface: 始め, base: 始める, pos: 動詞, pos1: 自立), Morph(surface: て, base: て, pos: 助詞, pos1: 接続助詞)]),
Chunk(id: 3, dst: 4, srcs: ['2'], morphs: [Morph(surface: 人間, base: 人間, pos: 名詞, pos1: 一般), Morph(surface: という, base: という, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 4, dst: 5, srcs: ['3'], morphs: [Morph(surface: もの, base: もの, pos: 名詞, pos1: 非自立), Morph(surface: を, base: を, pos: 助詞, pos1: 格助詞)]),
Chunk(id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(surface: 見, base: 見る, pos: 動詞, pos1: 自立), Morph(surface: た, base: た, pos: 助動詞, pos1: *), Morph(surface: 。, base: 。, pos: 記号, pos1: 句点)])]]
ans_42 = []
for chunks in book:
for c in chunks:
if int(c.dst) != -1:
ans_42.append('{}\t{}'.format(
surface_from(c.morphs),
surface_from([d.morphs for d in chunks if d.id == c.dst][0])
))
print(len(ans_42))
print('\n'.join(ans_42[:30]))
71771
猫である。
吾輩は 猫である。
名前は 無い。
まだ 無い。
どこで 生れたか
生れたか つかぬ。
とんと つかぬ。
見当が つかぬ。
何でも 薄暗い
薄暗い 所で
じめじめした 所で
所で 泣いて
ニャーニャー 泣いて
泣いて 記憶している。
いた事だけは 記憶している。
吾輩は 見た。
ここで 始めて
始めて 人間という
人間という ものを
ものを 見た。
しかも 種族であったそうだ。
あとで 聞くと
聞くと 種族であったそうだ。
それは 種族であったそうだ。
書生という 人間中で
人間中で 種族であったそうだ。
一番 獰悪な
獰悪な 種族であったそうだ。
この 書生というのは
書生というのは 話である。
43. Trích xuất các dependency relations giữa các chunk chứa danh từ và các chunk chứa động từ
Trích xuất các dependency relations giữa các chunk chứa danh từ và các chunk chứa động từ và in ra nội dung text trên mỗi dùng và các thành phần cách nhau bởi dấu cách. Tương tự như bài 42, không hiển thị các dấu (punctuation marks) trong các chunk.
ans_43 = []
for chunks in book:
for c in chunks:
if (
int(c.dst) != -1
and '名詞' in poss_from(c.morphs)
and '動詞' in poss_from([d.morphs for d in chunks if d.id == c.dst][0])
):
ans_43.append('{}\t{}'.format(
surface_from(c.morphs),
surface_from([d.morphs for d in chunks if d.id == c.dst][0])
))
print(len(ans_43))
print('\n'.join(ans_43[:30]))
29106
どこで 生れたか
見当が つかぬ。
所で 泣いて
ニャーニャー 泣いて
いた事だけは 記憶している。
吾輩は 見た。
ここで 始めて
ものを 見た。
あとで 聞くと
我々を 捕えて
掌に 載せられて
スーと 持ち上げられた
時 フワフワした
感じが あったばかりである。
上で 落ちついて
顔を 見たのが
ものの 見始であろう。
ものだと 思った
感じが 残っている。
今でも 残っている。
第一毛をもって 装飾されべきはずの
顔が つるつるして
その後 逢ったが
猫にも 逢ったが
一度も 出会わした
真中が 突起している。
中から 吹く。
ぷうぷうと煙を 吹く。
咽せぽくて 弱った。
人間の 飲む
44. Visualize cây dependency
Visualize cây phụ thuộc của câu đã cho dưới dạng biểu đồ có hướng. Để visualize, có thể chuyển đổi cây phụ thuộc sang ngôn ngữ DOT và sử dụng Graphviz. Thêm nữa, khi visualize một đồ thị có hướng trong Python, có thể sử dụng pydot.
def visualize_chunks(chunks):
edges = []
for c in chunks:
if int(c.dst) != -1:
edges.append((
surface_from(c.morphs),
surface_from([d.morphs for d in chunks if d.id == c.dst][0])
))
n = pydot.Node('node')
n.fontname = "ipagp.ttf"
g = pydot.graph_from_edges(edges, directed=True)
g.add_node(n)
display(Image(g.create_png()))
visualize_chunks(book[6])
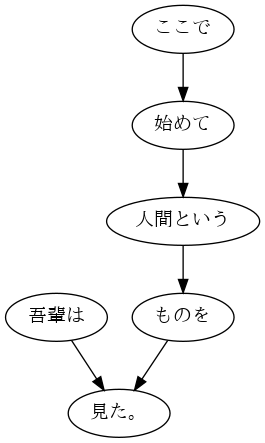
45. Trích xuất case pattern của động từ
Yêu cầu của bài tập này là tìm hiểu (investigate) về case frame trong tiếng Nhật sử dụng dữ liệu trong file đầu vào neko.txt. Coi các động từ là vị ngữ (predicate), các trợ từ (như が,を,...) của chunk liên kết với với động từ là các case, hãy in ra các vị ngữ và các "case" theo định dạng cách nhau bởi ký tự tab. Output của chương trình cần thoả mãn các điều kiện sau:
- Ở các chunk có chứa động từ, sử dụng dạng nguyên thể của động từ trái nhất làm vị ngữ.
- Coi các trợ từ liên kết với các vị ngữ là các "case" trong case frame.
- Nếu một vị ngữ được liên kết bởi nhiều trợ từ (chunk), in tất cả các trợ từ theo thứ tự từ điển. Các trợ từ cách nhau bởi dấu cách
Xem xét ví dụ sau: 吾輩はここで始めて人間というものを見た (câu thứ 8 trong file neko.txt.cabocha). Câu này gồm hai động từ 始める và 見る. Nếu trong kết quả phân tích cú pháp, động từ 始める liên kết với chunk ここで, động từ 見る liên kết với với chunk 吾輩は và ものを, chương trình sẽ in ra:
始める で
見る は を
Lưu output của chương trình ra file, xác nhận các mục sau chỉ với các lệnh của Unix.
- Kết hợp của các vị ngữ và case phổ biển trong corpus.
- Các case patterns của các động từ する, 見る, 与える (theo thứ tự từ cao đến thấp của tần suất xuất hiện trong corpus).
kakus = []
for c in chunks:
for m in c.morphs:
if m.pos == '動詞':
jutsugo = m.base
joshi = []
for src_ms in [src_c.morphs for src_c in chunks if src_c.id in c.srcs]:
try:
joshi.append([j.base for j in src_ms if j.pos == '助詞'][-1])
except:
continue
kakus.append(jutsugo + '\t' + ' '.join(sorted(joshi)))
break
return kakus
kakus = []
for chunks in book:
kakus += kaku_pattern(chunks)
with open('kaku_pattern.txt', 'w') as f:
f.write('\n'.join(kakus))
!head -n 20 kaku_pattern.txt
生れる で
つく か が
する
泣く で
する て は
始める で
見る は を
聞く で
捕える を
煮る て
食う て
思う から
載せる に
持ち上げる て と
する
ある が
落ちつく で
見る て を
見る の
思う と
!sort < kaku_pattern.txt | uniq -c | sort -n -k 1 -r | head -n 20
2646 ある が
1559 つく か が
985 する
840 云う は
553 する が で と
380 つかむ を
364 思う と
334 見る の
257 かく たり を
253 かかる が て
214 かける
205 ある まで
197 云う と に
144 出る も
144 する と は は は
136 見える と
129 聞く で
123 行く へ
122 云う
121 見る は を
!grep '^する' kaku_pattern.txt | cut -d $'\t' -f 2 | sed -e 's/ /\n/g' | sort | uniq -c | sort -n -k 1 -r | head -n 20
4979 て
452 まで
435
98 として
33 をもって
3 と共に
3 にあたって
2 に対して
1 に従って
1 に対し
!grep '^見る' kaku_pattern.txt | cut -d $'\t' -f 2 | sed -e 's/ /\n/g' | sort | uniq -c | sort -n -k 1 -r | head -n 20
827 は
82 より
80
12 ばかり
1 に従って
1 によって
!grep '^与える' kaku_pattern.txt | cut -d $'\t' -f 2 | sed -e 's/ /\n/g' | sort | uniq -c | sort -n -k 1 -r | head -n 20
53 に
1 けれども
1 として
46. Trích xuất thông tin của case pattern của động từ
Chỉnh sửa bài tập 45, trích xuất thêm các chunks mà các vị ngữ (predicate) liên kết tới. In ra theo định dạng tab. Ngoài các điều kiện đưa ra ở bài tập 45, output phải thoả mãn các điều kiện sau.
- Các modifier là dãy các word của các chunk liên kết tới vị ngữ (không cần phải xoá đuôi và các trợ từ).
- Trong trường hợp một predicate liên kết với nhiều chunk (bunsetsu), in ra các chunk này theo thứ tự của các trợ từ trong các chunk. Dùng ký tự space để ngăn cách giữa các chunk.
Xem xét ví dụ sau: 吾輩はここで始めて人間というものを見た (câu thứ 8 trong file neko.txt.cabocha). Câu này gồm hai động từ 始める và 見る. Nếu trong kết quả phân tích cú pháp, động từ 始める liên kết với chunk ここで, động từ 見る liên kết với với chunk 吾輩は và ものを, chương trình sẽ in ra:
始める で ここで
見る は を 吾輩は ものを
def kaku_pattern2(chunks):
kakus = []
for c in chunks:
for m in c.morphs:
if m.pos == '動詞':
jutsugo = m.base
joshi = []
for src_ms in [src_c.morphs for src_c in chunks if src_c.id in c.srcs]:
try:
joshi.append([(j.base, surface_from(src_ms)) for j in src_ms if j.pos == '助詞'][-1])
except:
continue
joshi_ = sorted(joshi, key=lambda x: x[0])
kakus.append(
jutsugo
+ '\t'
+ ' '.join([x[0] for x in joshi_])
+ '\t'
+ ' '.join([x[1] for x in joshi_])
)
break
return kakus
kakus = []
for chunks in book:
kakus += kaku_pattern2(chunks)
with open('kaku_pattern2.txt', 'w') as f:
f.write('\n'.join(kakus))
!head -n 20 kaku_pattern2.txt
生れる で どこで
つく か が 生れたか 見当が
する
泣く で 所で
する て は 泣いて いた事だけは
始める で ここで
見る は を 吾輩は ものを
聞く で あとで
捕える を 我々を
煮る て 捕えて
食う て 煮て
思う から なかったから
載せる に 掌に
持ち上げる て と 載せられて スーと
する
ある が 感じが
落ちつく で 上で
見る て を 落ちついて 顔を
見る の ものの
思う と ものだと
47. Mining các cấu trúc câu có động từ chức năng
(cấu trúc này có tên tiếng Nhật là 機能動詞構文)
Bài tập này tập trung vào các case frame を của các động từ, trong đó động từ có dạng liên kết サ変接続名詞. Sửa chương trình trong bài tập 46 để thoả mãn các yêu cầu sau đây.
- Bài tập này tập trung vào các bunsetsu có dạng 「サ変接続名詞+を(助詞)」 liên kết với động từ.
- Biến đổi các vị ngữ về dạng 「サ変接続名詞+を+動詞の基本形」. Nếu trong 1 chunk có nhiều động từ, sử dụng động từ bên trái nhất.
- Trong trường hợp một vĩ ngữ có liên kết với nhiều trợ từ (chunk), in tất cả các trợ từ này theo thứ tự từ điển. Các trợ từ cách nhau bởi dấu cách.
- Trong trường hợp có nhiều chunks liên kết với một vị ngữ (predicate), in tất cả các chunk này đồng nhất với thứ tự in của các trợ từ mà nó bao gồm. Các chunk được cách nhau bởi ký tự space.
Ví dụ, cho câu sau. 「別段くるにも及ばんさと、主人は手紙に返事をする。」. Chương trình sẽ in ra kết quả sau.
返事をする と に は 及ばんさと 手紙に 主人は
Lưu kết quả của chương trình ra file, chỉ sử dụng lệnh unix để xác nhận:
- Các vị ngữ thường gặp trong corpus (danh từ liên kết sahen + động từ)
- Các vị ngữ và các case patterns thường xuất hiện trong văn bản.
def kaku_pattern3(chunks):
kakus = []
is_sahen = False
is_wo = False
for c in chunks:
for m in c.morphs:
if m.pos1 == 'サ変接続':
sahen = m.surface
is_sahen = True
if is_sahen and m.surface == 'を':
sahen += m.surface
is_wo = True
if (
is_sahen
and is_wo
and m.base == 'する'
):
sahen += m.base
joshi = []
for src_ms in [src_c.morphs for src_c in chunks if src_c.id in c.srcs]:
try:
joshi.append([(j.base, surface_from(src_ms)) for j in src_ms if j.pos == '助詞'][-1])
except:
continue
joshi_ = [j for j in joshi if j[1] not in sahen]
joshi__ = sorted(joshi_, key=lambda x: x[0])
j = ' '.join([x[0] for x in joshi__])
b = ' '.join([x[1] for x in joshi__])
if j != '' and b != '':
kakus.append(sahen + '\t' + j + '\t' + b)
is_sahen = False
is_wo = False
break
return kakus
kakus = []
for chunks in book:
kakus += kaku_pattern3(chunks)
with open('kaku_pattern3.txt', 'w') as f:
f.write('\n'.join(kakus))
!head -n 20 kaku_pattern3.txt
決心をする と こうと
返報をする んで 偸んで
昼寝をする が 彼が
観察する て を 同居して 彼等を
生活をする が を を 我等猫族が 愛を 家族的生活を
憤慨する て に いって 大に
投書をする て へ やって ほととぎすへ
話をする に 時に
昼寝をする て 出て
写生する として に は を 結果として 手初めに 彼は 吾輩を
失敬をする て の へ を 失敬して 存分の 前へ 両足を
欠伸をする から て て なったから、 して、 押し出して
失望ををする を 声を
報道をする に 耳に
運動をする が と は を 二時頃であったが、 茶園へと 吾輩は 歩を
佇立する て と に 忘れて 念と、 前に
雑談をする ながら は 寝転びながら 黒は
質問する て で と の の は 向って あとで、 していると、 例のごとく 下のごとく 彼は
感心する て を あって、 気焔を
弁護する を 己れを
!cut -d $'\t' -f 1 < kaku_pattern3.txt | sort | uniq -c | sort -n -k 1 -r | head -n 20
26 返事をする
20 挨拶をする
17 ——をする
13 話をする
9 喧嘩をする
7 呈出する
6 研究する
6 真似をする
6 我慢する
5 運動をする
5 質問をする
5 説明する
5 相談をする
5 発見する
5 注意をする
5 欠伸をする
5 昼寝をする
5 主張する
4 降参をする
4 辞儀をする
!awk -F '\t' '{split($2, k, " "); for(i in k)print $1, k[i]}' kaku_pattern3.txt | sort | uniq -c | sort -n -k 1 -r | head -n 20
47 返事をする と
28 挨拶をする で
24 ——をする と
19 呈出する は
18 話をする に
13 欠伸をする て
12 辞儀をする が
10 研究する を
10 真似をする で
10 応用する が
10 喧嘩をする で
9 質問する て
9 注意をする を
9 ——ををする を
8 頂戴する て
8 運動をする が
8 発見する を
8 昼寝をする が
8 我慢する を
8 感心する て
48. Trích xuất ra dependency path từ các danh từ đến gốc
Chương trình yêu cầu trích xuất ra depedency path từ các chunk có chứa danh từ đến root của cây depedency. Các dependency path phải thoả mãn yêu cầu sau đây.
- Biểu diễn các chunk (bunsetsu) dưới dạng chuỗi của các morpheme (surface form)
- Biểu diễn liên kết giữa các bunsetsu bằng ký tự mũi tên
->.
Ví dụ, đầu ra cho câu ví dụ 「吾輩はここで始めて人間というものを見た」(câu thứ 8 trong file neko.txt.cabocha) như sau:
吾輩は -> 見た
ここで -> 始めて -> 人間という -> ものを -> 見た
人間という -> ものを -> 見た
ものを -> 見た
def make_path(chunk, chunks):
if int(chunk.dst) == -1:
return [surface_from(chunk.morphs)]
return [surface_from(chunk.morphs)] + make_path(
[c for c in chunks if chunk.dst == c.id][0],
chunks
)
def path_to_root(chunks):
paths = []
for c in chunks:
if '名詞' in poss_from(c.morphs):
paths.append(make_path(c, chunks))
return paths
paths = path_to_root(book[6])
print('\n'.join([' -> '.join(p) for p in paths]))
吾輩は -> 見た。
ここで -> 始めて -> 人間という -> ものを -> 見た。
人間という -> ものを -> 見た。
ものを -> 見た。
paths = []
for chunks in book:
paths += path_to_root(chunks)
print('\n'.join([' -> '.join(p) for p in paths[:30]]))
一
吾輩は -> 猫である。
猫である。
名前は -> 無い。
どこで -> 生れたか -> つかぬ。
見当が -> つかぬ。
何でも -> 薄暗い -> 所で -> 泣いて -> 記憶している。
所で -> 泣いて -> 記憶している。
ニャーニャー -> 泣いて -> 記憶している。
いた事だけは -> 記憶している。
記憶している。
吾輩は -> 見た。
ここで -> 始めて -> 人間という -> ものを -> 見た。
人間という -> ものを -> 見た。
ものを -> 見た。
あとで -> 聞くと -> 種族であったそうだ。
それは -> 種族であったそうだ。
書生という -> 人間中で -> 種族であったそうだ。
人間中で -> 種族であったそうだ。
一番 -> 獰悪な -> 種族であったそうだ。
獰悪な -> 種族であったそうだ。
種族であったそうだ。
書生というのは -> 話である。
我々を -> 捕えて -> 煮て -> 食うという -> 話である。
話である。
当時は -> なかったから -> 思わなかった。
何という -> 考も -> なかったから -> 思わなかった。
考も -> なかったから -> 思わなかった。
彼の -> 掌に -> 載せられて -> 持ち上げられた -> 時 -> フワフワした -> 感じが -> あったばかりである。
掌に -> 載せられて -> 持ち上げられた -> 時 -> フワフワした -> 感じが -> あったばかりである。
49. Trích xuất ra chuỗi liên kết giữa các danh từ
Trích xuất dependency path ngắn nhất liên kết giữa các cặp noun chunk. Đối với cặp noun chunk với index tương ứng là i và j (i < j), các dependency paths thoả mãn các yêu cầu sau.
- Giống như bài 48, biểu diễn liên kết giữa các bunsetsu bằng ký tự mũi tên (->).
- Thay các noun chunk i, và j tương ứng thành X và Y.
Thêm nữa, các dependency path trong bài tập này có thể được diễn dịch như sau.
- Trên đường đi của noun chunk i tới gốc của cây, nếu tồn tại noun chunk j: trích xuất dependency path giữa noun chunk i và noun chunk j.
- Ngoài trường hợp nói trên, nếu đường đi của noun chunk i và noun chunk j tới gốc của cây cắt nhau ở bunsetsu k: In ra đường đi từ i tới bunsetsu ngay trước k và đường đi từ bunsetsu j tới bunsetsu ngay trước k. Biểu diễn liên kết với bunsetsu k bằng ký tự |.
Ví dụ, kết quả đưa ra cho câu ví dụ 「吾輩はここで始めて人間というものを見た」(câu thứ 8 trong file neko.txt.cabocha) như sau:
Xは | Yで -> 始めて -> 人間という -> ものを | 見た
Xは | Yという -> ものを | 見た
Xは | Yを | 見た
Xで -> 始めて -> Y
Xで -> 始めて -> 人間という -> Yを
Xという -> Y
def make_path2(c1, c2, chunks, X=False):
s = ''
if int(c1.id) == int(c2.id):
for m in c2.morphs:
if m.pos == '名詞':
return [s + 'Y']
else:
s += m.surface
else:
for m in c1.morphs:
if X and m.pos == '名詞':
X = False
s += 'X'
else:
s += m.surface
return [s] + make_path2(
[c for c in chunks if c1.dst == c.id][0],
c2,
chunks
)
def make_path3(c1, c2, chunks, X=False, Y=False):
s = ''
for m in c1.morphs:
if X and m.pos == '名詞':
X = False
s += 'X'
elif Y and m.pos == '名詞':
Y = False
s += 'Y'
else:
s += m.surface
if int(c1.id) == int(c2.id):
return [s]
else:
return [s] + make_path3(
[c for c in chunks if c1.dst == c.id][0],
c2,
chunks
)
def get_path(start, goal, pred):
return get_path_row(start, goal, pred[start])
def get_path_row(start, goal, pred_row):
path = []
i = goal
while i != start and i >= 0:
path.append(i)
i = pred_row[i]
if i < 0:
return []
path.append(i)
return path[::-1]
def path_to_root(chunks):
route = np.zeros((len(chunks), len(chunks)))
for c in chunks:
if int(c.dst) != -1:
route[int(c.id), int(c.dst)] = 1
_, pre = shortest_path(route, directed=False, return_predecessors=True)
norm_in_c = [c for c in chunks if '名詞' in poss_from(c.morphs)]
paths = []
for cs in itertools.combinations(norm_in_c, 2):
route = get_path(int(cs[0].id), int(cs[1].id), pre)
if max(route) == route[-1]:
path = make_path2(cs[0], cs[1], chunks, True)
paths.append(' -> '.join(path))
else:
for i, r in enumerate(route):
if route[i] > route[i+1]:
px = make_path3(
cs[0],
[c for c in chunks if int(c.id) == route[i-1]][0],
chunks,
X=True
)
py = make_path3(
cs[1],
[c for c in chunks if int(c.id) == route[i+1]][0],
chunks,
Y=True
)
pz = make_path3(
[c for c in chunks if int(c.id) == route[i]][0],
[c for c in chunks if int(c.id) == route[i]][0],
chunks
)
break
paths.append(' | '.join([
' -> '.join(px),
' -> '.join(py),
' -> '.join(pz)
]))
return paths
paths = path_to_root(book[6])
pprint(paths)
['Xは | Yで -> 始めて -> 人間という -> ものを | 見た。',
'Xは | Yという -> ものを | 見た。',
'Xは | Yを | 見た。',
'Xで -> 始めて -> Y',
'Xで -> 始めて -> 人間という -> Y',
'Xという -> Y']
paths = []
for chunks in book:
paths += path_to_root(chunks)
print('\n'.join(paths[:30]))
Xは -> Y
Xで -> 生れたか | Yが | つかぬ。
Xでも -> 薄暗い -> Y
Xでも -> 薄暗い -> 所で | Y | 泣いて
Xでも -> 薄暗い -> 所で -> 泣いて | Yだけは | 記憶している。
Xでも -> 薄暗い -> 所で -> 泣いて -> Y
Xで | Y | 泣いて
Xで -> 泣いて | Yだけは | 記憶している。
Xで -> 泣いて -> Y
X -> 泣いて | Yだけは | 記憶している。
X -> 泣いて -> Y
Xだけは -> Y
Xは | Yで -> 始めて -> 人間という -> ものを | 見た。
Xは | Yという -> ものを | 見た。
Xは | Yを | 見た。
Xで -> 始めて -> Y
Xで -> 始めて -> 人間という -> Y
Xという -> Y
Xで -> 聞くと | Yは | 種族であったそうだ。
Xで -> 聞くと | Yという -> 人間中で | 種族であったそうだ。
Xで -> 聞くと | Y中で | 種族であったそうだ。
Xで -> 聞くと | Y -> 獰悪な | 種族であったそうだ。
Xで -> 聞くと | Yな | 種族であったそうだ。
Xで -> 聞くと -> Y
Xは | Yという -> 人間中で | 種族であったそうだ。
Xは | Y中で | 種族であったそうだ。
Xは | Y -> 獰悪な | 種族であったそうだ。
Xは | Yな | 種族であったそうだ。
Xは -> Y
Xという -> Y
Chương 6: Machine Learning
Trong chương trình, chúng ta sẽ sử dụng bộ dữ liệu News Aggregator Data Set của Fabio Gasparatti và thực hiện bài toán phân loại tiêu đề của các bài báo thành "business", "science and technology", "entertainment", "health".
50. Tải và chuẩn bị dữ liệu
Tải xuống bộ dữ liệu News Aggregator Data Set, tạo ra dữ liệu huấn luyện (train.txt), dữ liệu kiểm chứng (valid.txt) và dữ liệu đánh giá (test.txt) theo hướng dẫn dưới đây.
- Giải nén file zip đã tải xuống, đọc hướng dẫn của file readme.txt
- Trích xuất ra các example (bài báo) của các báo "Reuters", "Huffington Post", "Businessweek", "Contactmusic.com", "Daily Mail".
- Sắp xếp lại các example đã trích xuất theo thứ tự ngẫu nhiên.
- Phân chia các example đã trích xuất với tỉ lệ 80% cho tập train, còn lại dùng 10% cho tập kiểm chứng và 10% cho tập đánh giá và lưu thành các file train.txt, valid.txt, test.txt. Trong các file, mỗi dòng lưu một example, tên của category và title của các bài báo được phân cách bởi dấu tab (Các file này sau này sẽ được dùng lại trong bài tập 70).
Sau khi tạo dữ liệu train và dữ liệu đánh giá, hãy thống kê số lượng example của các nhãn.
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip && unzip NewsAggregatorDataset.zip
from sklearn.model_selection import train_test_split
import pandas as pd
import csv
news_corpora = pd.read_table('newsCorpora.csv', header=None, quoting=csv.QUOTE_NONE)
#print(len(news_corpora)) # -> 422937
news_corpora.columns = ['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']
# 2. Chỉ trích xuất các trường hợp (bài báo) mà nguồn (nhà xuất bản) là “Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”.
news_corpora = news_corpora[news_corpora['PUBLISHER'].isin(
['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail'])]
# 3. Sắp xếp ngẫu nhiên các trường hợp đã trích xuất.
news_corpora = news_corpora.sample(frac=1, random_state=0)
# 4.1 80% các trường hợp được trích xuất được chia thành dữ liệu học tập và 10% còn lại được chia thành dữ liệu xác minh và dữ liệu đánh giá.
train, test_valid = train_test_split(news_corpora, test_size=0.2, random_state=0) # train:test&vaid = 8:2
test, valid = train_test_split(test_valid, test_size=0.5, random_state=0) # test : valid = 1:1
# Kiểm tra số lượng trường hợp
print("train={}, valid={}, test={}".format(len(train), len(valid), len(test)))
# 4.2 Lưu tệp với các tên tệp train.txt, valid.txt và test.txt, tương ứng.
train[['CATEGORY', 'TITLE']].to_csv('train.txt', sep='\t', index=False, header=None)
valid[['CATEGORY', 'TITLE']].to_csv('valid.txt', sep='\t', index=False, header=None)
test[['CATEGORY', 'TITLE']].to_csv('test.txt', sep='\t', index=False, header=None)
# Kiểm tra số lượng trường hợp
!wc -l train.txt valid.txt test.txt
# Số trường hợp trong mỗi loại dữ liệu đào tạo và dữ liệu đánh giá
print("each category of train data =", {cat: len(train[train['CATEGORY'].isin([cat])]) for cat in set(news_corpora['CATEGORY'])})
print("each category of test data =", {cat: len(test[test['CATEGORY'].isin([cat])]) for cat in set(news_corpora['CATEGORY'])})
51. Trích xuất đặc trưng
Trích xuất đặc trưng từ dữ liệu train, dữ liệu kiểm chứng và dữ liệu đánh giá, lưu vào các file tương ứng train.feature.txt, valid.feature.txt, test.feature.txt. Bạn có thể tự do thiết kế các đặc trưng có thể hữu ích cho việc phân loại. Baseline đơn giản nhất là dùng dùng dãy các từ trong title của bài báo làm đặc trưng.
import joblib
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
import string
class Feature:
def __init__(self):
self.vectorizer = None
# Quy trình tạo tính năng.
# Tạo một vectơ với tất cả các từ là các đối tượng địa lý.
# Vì là tiếng Anh nên không cần phân tích hình thái học
def create_feature(self, datatype):
X = pd.read_table('{}.txt'.format(datatype), header=None)
cols = ['CATEGORY', 'TITLE']
X.columns = cols
df = pd.concat([X]).reset_index(drop=True)
df["TITLE"] = df["TITLE"].str.normalize("NFKC")
df["TITLE"] = df["TITLE"].str.lower()
# Tôi đã dừng lại vì độ chính xác đã giảm xuống.
#for s in list(string.punctuation):
# df["TITLE"] = df["TITLE"].str.replace(s, "")
if datatype == 'train':
self.vectorizer = CountVectorizer()
bag = self.vectorizer.fit_transform(df['TITLE'])
joblib.dump(self.vectorizer.vocabulary_, 'ch06_vocabulary_.pkl')
else:
bag = self.vectorizer.transform(df['TITLE'])
df = pd.concat([df, pd.DataFrame(bag.toarray())], axis=1) # Xử lý dọc theo cột axis=0, Xử lý dọc theo dây chuyền axis=1
X = df.drop(cols, axis=1)
X.to_csv('{}.feature.txt'.format(datatype), sep='\t', index=False, header=None)
feature = Feature()
feature.create_feature(datatype='train')
feature.create_feature(datatype='valid')
feature.create_feature(datatype='test')
!wc -l *.feature.txt
!head -n 1 train.feature.txt
1336 test.feature.txt
10684 train.feature.txt
1336 valid.feature.txt
13356 total
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
52. Training
Dùng dữ liệu huấn luyện được tạo ra trong bài tập 51, hãy huấn luyện mô hình Logistic Regression.
import pandas as pd
import joblib
from sklearn.linear_model import LogisticRegression
from scipy.sparse import csr_matrix
cat_map = {'b': 0, 'e': 1, 't': 2, 'm': 3}
X_train = csr_matrix(pd.read_table('train.feature.txt', header=None))
y_train = pd.read_table('train.txt', header=None)[0].map(cat_map)
clf = LogisticRegression(max_iter=200)
clf.fit(X_train, y_train)
joblib.dump(clf, 'ch06_model.pkl')
['ch06_model.pkl']
53. Prediction
Sử dụng mô hình Logistic Regression đã huấn luyện trong bài 52, hãy cài đặt chương trình phân loại một tiêu đề của một bài báo cho trước và tính xác suất dự đoán.
X_test = csr_matrix(pd.read_table('test.feature.txt', header=None))
print(clf.predict(X_test))
print(clf.predict_proba(X_test))
[2 0 0 ... 0 1 1]
[[0.22797553 0.01546607 0.74540615 0.01115225]
[0.92473782 0.05988012 0.00581501 0.00956705]
[0.9873604 0.00600427 0.00138615 0.00524919]
...
[0.98047718 0.00617636 0.00928182 0.00406464]
[0.04720774 0.88928973 0.05602935 0.00747318]
[0.00362292 0.99319261 0.0011902 0.00199427]]
54. Tính độ chính xác của mô hình
Hãy tính độ chính xác của mô hình Logistic Regression đã học ở bài tập 52 trên tập dữ liệu huấn luyện (train) và tập dữ liệu đánh giá (test).
from sklearn.metrics import accuracy_score
X_train = csr_matrix(pd.read_table('train.feature.txt', header=None))
X_test = csr_matrix(pd.read_table('test.feature.txt', header=None))
y_train = pd.read_table('train.txt', header=None)[0].map(cat_map)
y_test = pd.read_table('test.txt', header=None)[0].map(cat_map)
print(f'train acc: {accuracy_score(y_train, clf.predict(X_train))}')
print(f'test acc: {accuracy_score(y_test, clf.predict(X_test))}')
train acc: 0.9958816922500936
test acc: 0.9041916167664671
55. Tạo Confusion Matrix
Tạo confusion matrix của mô hình Logistic Regression đã học ở bài tập 52 trên dữ liệu huấn luyện và dữ liệu đánh giá.
from sklearn.metrics import confusion_matrix
print(f'train confusion matrix:\n {confusion_matrix(y_train, clf.predict(X_train))}')
print(f'test confusion matrix:\n {confusion_matrix(y_test, clf.predict(X_test))}')
# memo: 混同行列
# https://aidemy.net/courses/2010/exercises/Sy2YnLsLeG
train confusion matrix:
[[4459 2 7 0]
[ 7 4248 2 0]
[ 17 5 1201 0]
[ 3 1 0 732]]
test confusion matrix:
[[560 17 15 4]
[ 6 503 2 4]
[ 28 17 95 4]
[ 13 16 2 50]]
56. Tính toán Precision, Recall và F1
Hãy tính Precision, Recall, F1 của mô hình Logistic Regression đã học ở bài tập 52 trên dữ liệu test. Tính Precision, Recall, F1 cho từng nhãn rồi tính các giá trị micro-average, macro-average cho các độ đo.
from sklearn.metrics import recall_score, precision_score, f1_score
y_test = pd.read_table('test.txt', header=None)[0].map(cat_map)
y_pred = clf.predict(X_test)
# memo:
# micro-> Trung bình xem xét sự mất cân bằng nhãn
# macro-> Trung bình không xem xét sự mất cân bằng nhãn (trung bình đơn giản)
print(f'test recall of None: {recall_score(y_test, y_pred, average=None)}')
print(f'test recall of micro: {recall_score(y_test, y_pred, average="micro")}')
print(f'test recall of macro: {recall_score(y_test, y_pred, average="macro")}')
print(f'test precision of None: {precision_score(y_test, y_pred, average=None)}')
print(f'test precision of micro: {precision_score(y_test, y_pred, average="micro")}')
print(f'test precision of macro: {precision_score(y_test, y_pred, average="macro")}')
print(f'test f1 of None: {f1_score(y_test, y_pred, average=None)}')
print(f'test f1 of micro: {f1_score(y_test, y_pred, average="micro")}')
print(f'test f1 of macro: {f1_score(y_test, y_pred, average="macro")}')
test recall of None: [0.93959732 0.97669903 0.65972222 0.61728395]
test recall of micro: 0.9041916167664671
test recall of macro: 0.7983256293504903
test precision of None: [0.92257002 0.90958409 0.83333333 0.80645161]
test precision of micro: 0.9041916167664671
test precision of macro: 0.8679847623775752
test f1 of None: [0.93100582 0.94194757 0.73643411 0.6993007 ]
test f1 of micro: 0.9041916167664671
test f1 of macro: 0.8271720480393174
57. Xác nhận độ quan trọng của các features
Trong mô hình Logistic Regression đã học ở bài tập 52, hãy xác nhận top-10 các features có trọng số cao nhất và top-10 các features có trọng số thấp nhất.
import joblib
feature_list = feature.vectorizer.get_feature_names()
coefs = clf.coef_
for c, y in zip(coefs, sorted(cat_map.keys(), key=lambda x: x[0])):
d = dict(zip(feature_list, c))
top = sorted(d.items(), key=lambda x: abs(x[1]), reverse=True)[:10]
print("--- Trọng số của hàm xác định danh mục ---".format(y))
print("top10: ", top)
bottom = sorted(d.items(), key=lambda x: abs(x[1]), reverse=False)[:10]
print("bottom10: ", bottom)
--- Trọng số của hàm xác định danh mục ---
top10: [('bank', 1.876263118619227), ('ecb', 1.773164542417276), ('activision', -1.6918439691317437), ('fed', 1.687485617637653), ('ukraine', 1.5694060792539481), ('yellen', 1.5059620931456277), ('obamacare', 1.505939975991216), ('aereo', -1.4930498189068089), ('oil', 1.4878413759242382), ('china', 1.4708110408486683)]
bottom10: [('narrowed', -1.3124903552688761e-05), ('upstage', -1.4816353135830973e-05), ('christmas', -1.8066370205789546e-05), ('fills', -2.10992224936673e-05), ('editing', -2.1117885717046528e-05), ('tone', -2.1595721370196385e-05), ('active', -2.207307655213237e-05), ('picked', -2.341086672364166e-05), ('opposed', 2.4076425771671667e-05), ('outsell', -2.7119879321725062e-05)]
--- Trọng số của hàm xác định danh mục ---
top10: [('kardashian', 1.594016843785185), ('chris', 1.5752416643333391), ('google', -1.5677745154701448), ('paul', 1.434871877481855), ('miley', 1.3787309254607383), ('cyrus', 1.3242145513081836), ('transformers', 1.3208216816535678), ('cannes', 1.3042681001557603), ('george', 1.2917758737924543), ('film', 1.2674767192331027)]
bottom10: [('bodes', -1.663722179465473e-05), ('type', 1.9865274055673748e-05), ('tilts', -2.3072147649244527e-05), ('sectors', -2.696653197680159e-05), ('rapid', -2.963685498663584e-05), ('narrowed', 3.648866724454934e-05), ('upstage', 4.003510167936316e-05), ('appreciated', -4.1087169410835e-05), ('revives', -4.778575847314593e-05), ('damping', -5.286711217127587e-05)]
--- Trọng số của hàm xác định danh mục ---
top10: [('facebook', 2.654977543566242), ('google', 2.541541828620165), ('apple', 2.3878887278805982), ('climate', 2.3840423330920184), ('microsoft', 2.3795374509399414), ('tesla', 2.011269090062214), ('activision', 1.8852821896456906), ('nasa', 1.8333437835270092), ('neutrality', 1.7440654081591918), ('heartbleed', 1.6826886530328728)]
bottom10: [('upstage', -1.0016504986029477e-05), ('narrowed', -1.1038430004282905e-05), ('editing', -1.287017093652466e-05), ('snapchat', 1.5210033576998639e-05), ('active', -1.825468027781879e-05), ('enhances', -2.499640812462123e-05), ('familiar', -2.7428110590412376e-05), ('outsell', -2.8016697057317795e-05), ('slender', -3.178150713787913e-05), ('christmas', -3.567678344686811e-05)]
--- Trọng số của hàm xác định danh mục ---
top10: [('ebola', 2.721263517321827), ('fda', 2.2592724177077903), ('cancer', 2.0749680523322755), ('study', 1.851203667930392), ('drug', 1.8314169791285693), ('mers', 1.820035182504678), ('cases', 1.7924750717348579), ('medical', 1.59246514795901), ('cigarettes', 1.5768866041526384), ('brain', 1.5705515624344961)]
bottom10: [('tilts', -1.1399015281906812e-05), ('narrowed', -1.2325333687431842e-05), ('upstage', -1.5202243557643635e-05), ('editing', -2.6309156053322982e-05), ('smokes', -2.638637143137516e-05), ('fills', -2.7752932605468435e-05), ('active', -3.253918731520774e-05), ('brushed', -3.409620990381145e-05), ('blige', -3.814912126583876e-05), ('ew', -3.888813986147589e-05)]
/usr/local/lib/python3.7/dist-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
warnings.warn(msg, category=FutureWarning)
58. Thay đổi tham số hiệu chỉnh (regularizer)
Khi huấn luyện mô hình Logistic Regression, bằng việc thay đổi tham số hiệu chỉnh (Regularization), chúng ta có thể kiểm soát được vấn đề overfitting. Hãy huấn luyện mô hình Logistic Regression bằng các tham số hiệu chỉnh khác nhau và tính độ chính xác trên các tập train, valid và test. Hãy tổng hợp kết quả thực nghiệm trên đồ thị với trục hoành là tham số hiệu chỉnh và trục tung là độ chính xác.
import matplotlib.pyplot as plt
X_valid = csr_matrix(pd.read_table('valid.feature.txt', header=None))
y_valid = pd.read_table('valid.txt', header=None)[0].map(cat_map)
C_candidate = [0.1, 0.5, 1.0, 1.5, 2.0, 2.5]
train_acc = []
valid_acc = []
test_acc = []
for c in C_candidate:
clf = LogisticRegression(max_iter=1000, C=c)
clf.fit(X_train, y_train)
train_acc.append(accuracy_score(y_train, clf.predict(X_train)))
valid_acc.append(accuracy_score(y_valid, clf.predict(X_valid)))
test_acc.append(accuracy_score(y_test, clf.predict(X_test)))
plt.plot(C_candidate, train_acc, label='train acc')
plt.plot(C_candidate, valid_acc, label='valid acc')
plt.plot(C_candidate, test_acc, label='test acc')
plt.legend()
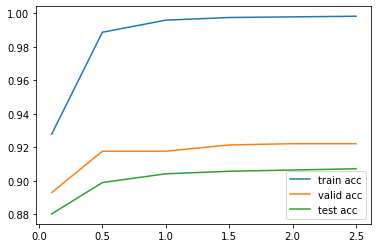
59. Hyperparameter Search
Hãy vừa thay đổi thuật toán học máy và các hyperparameter vừa huấn luyện mô hình phân loại. Đưa ra thuật toán học máy, hyperparameter đạt kết quả tốt nhất trên tập valid. Sau đó tính độ chính xác trên tập test sử dụng thuật toán học máy - hyperparameters đã xác định.
import itertools
import warnings
warnings.simplefilter('ignore')
def search_best_param(grid_param, estimator, verbose=False):
best_acc = 0
best_param = {}
product = [x for x in itertools.product(*grid_param.values())]
params = [dict(zip(grid_param.keys(), r)) for r in product]
for param in params:
estimator.set_params(**param)
estimator.fit(X_train, y_train)
acc = accuracy_score(y_valid, clf.predict(X_valid))
if verbose:
print(param, acc)
if acc > best_acc:
best_acc = acc
best_param = param
return best_param, best_acc
Hồi quy logistic
%%time
# Tìm kiếm thông số
candidate = []
# solver=liblinear ngoại trừ
grid_param = {
"penalty": ["l2", "none"],
"C": [2.7, 3.0, 3.5],
"solver":["newton-cg", "sag", "saga", "lbfgs"],
"max_iter": [36, 37, 38]
}
clf = LogisticRegression()
candidate.append(search_best_param(grid_param, clf))
# solver=liblinear
grid_param = {
"penalty" : ["l1", "l2"],
"C": [2.5, 4.0, 4.5, 5.0],
"solver":["liblinear"],
"max_iter": [20, 50, 100]
}
clf = LogisticRegression()
candidate.append(search_best_param(grid_param, clf))
best_param, best_score = sorted(candidate, key=lambda x: x[1], reverse=True)[0]
print(best_param, best_score)
{'penalty': 'none', 'C': 2.7, 'solver': 'saga', 'max_iter': 36} 0.9311377245508982
CPU times: user 1min 46s, sys: 1min 7s, total: 2min 53s
Wall time: 1min 34s
Máy vectơ hỗ trợ
%%time
from pprint import pprint
from sklearn.svm import SVC
candidate = []
grid_param = {
"C": [4.5, 4.7, 5.0, 5.1, 5.5],
"max_iter": [500, 1000, 2000]
}
clf = SVC()
candidate.append(search_best_param(grid_param, clf))
best_param, best_score = sorted(candidate, key=lambda x: x[1], reverse=True)[0]
pprint(best_param)
print(best_score)
{'C': 4.5, 'max_iter': 1000}
0.9169161676646707
CPU times: user 2min 18s, sys: 438 ms, total: 2min 18s
Wall time: 2min 18s
Random Forest algorithm
%%time
from pprint import pprint
from sklearn.ensemble import RandomForestClassifier
candidate = []
grid_param = {
"max_depth": [None],
"n_estimators": [1000, 2000],
"max_features": [10],
"min_samples_split": [5],
"min_samples_leaf": [1],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
clf = RandomForestClassifier()
candidate.append(search_best_param(grid_param, clf))
best_param, best_score = sorted(candidate, key=lambda x: x[1], reverse=True)[0]
pprint(best_param)
print(best_score)
{'bootstrap': False,
'criterion': 'gini',
'max_depth': None,
'max_features': 10,
'min_samples_leaf': 1,
'min_samples_split': 5,
'n_estimators': 2000}
0.8952095808383234
CPU times: user 15min 7s, sys: 3.24 s, total: 15min 10s
Wall time: 15min 11s
Tính accuracy_score của dữ liệu train với tham số thuật toán huấn luyện có tỷ lệ chính xác cao nhất trên dữ liệu Test.
%%time
best_clf = LogisticRegression()
best_clf.set_params(**{'penalty': 'none', 'C': 2.7, 'solver': 'saga', 'max_iter': 36})
best_clf.fit(X_train, y_train)
print(accuracy_score(y_test, best_clf.predict(X_test)))
0.9101796407185628
CPU times: user 285 ms, sys: 1.82 ms, total: 287 ms
Wall time: 292 ms
Chương 7: Word Vectors
Liên quan đến word vector (word embedding) biểu diễn ý nghĩa của các từ bằng vector số thực, hãy cài đặt chương trình thực hiện các xử lý sau đây
60. Đọc và hiển thị word vector
Download bộ word vectors (3,000,000 từ-phrases, 300 chiều) đã được huấn luyện trên tập dữ liệu Google News (khoảng 100 tỉ từ), hiển thị word vector của từ "United States". Chú ý rằng thực tế, bên trong mô hình, từ "United States" được biểu diễn bằng "United_States".
FILE_ID = "0B7XkCwpI5KDYNlNUTTlSS21pQmM"
FILE_NAME = "GoogleNews-vectors-negative300.bin.gz"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
from gensim.models import KeyedVectors
#Load mô hình được đào tạo
model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz', binary=True)
# Hiển thị vector từ
model['United_States']
5.61523438e-02, 1.51367188e-01, 4.29687500e-02, -2.08007812e-01,
-4.78515625e-02, 2.78320312e-02, 1.81640625e-01, 2.20703125e-01,
-3.61328125e-02, -8.39843750e-02, -3.69548798e-05, -9.52148438e-02,
-1.25000000e-01, -1.95312500e-01, -1.50390625e-01, -4.15039062e-02,
1.31835938e-01, 1.17675781e-01, 1.91650391e-02, 5.51757812e-02,
-9.42382812e-02, -1.08886719e-01, 7.32421875e-02, -1.15234375e-01,
8.93554688e-02, -1.40625000e-01, 1.45507812e-01, 4.49218750e-02,
-1.10473633e-02, -1.62353516e-02, 4.05883789e-03, 3.75976562e-02,
-6.98242188e-02, -5.46875000e-02, 2.17285156e-02, -9.47265625e-02,
4.24804688e-02, 1.81884766e-02, -1.73339844e-02, 4.63867188e-02,
-1.42578125e-01, 1.99218750e-01, 1.10839844e-01, 2.58789062e-02,
-7.08007812e-02, -5.54199219e-02, 3.45703125e-01, 1.61132812e-01,
-2.44140625e-01, -2.59765625e-01, -9.71679688e-02, 8.00781250e-02,
-8.78906250e-02, -7.22656250e-02, 1.42578125e-01, -8.54492188e-02,
-3.18359375e-01, 8.30078125e-02, 6.34765625e-02, 1.64062500e-01,
-1.92382812e-01, -1.17675781e-01, -5.41992188e-02, -1.56250000e-01,
-1.21582031e-01, -4.95605469e-02, 1.20117188e-01, -3.83300781e-02,
5.51757812e-02, -8.97216797e-03, 4.32128906e-02, 6.93359375e-02,
8.93554688e-02, 2.53906250e-01, 1.65039062e-01, 1.64062500e-01,
-1.41601562e-01, 4.58984375e-02, 1.97265625e-01, -8.98437500e-02,
3.90625000e-02, -1.51367188e-01, -8.60595703e-03, -1.17675781e-01,
-1.97265625e-01, -1.12792969e-01, 1.29882812e-01, 1.96289062e-01,
1.56402588e-03, 3.93066406e-02, 2.17773438e-01, -1.43554688e-01,
6.03027344e-02, -1.35742188e-01, 1.16210938e-01, -1.59912109e-02,
2.79296875e-01, 1.46484375e-01, -1.19628906e-01, 1.76757812e-01,
1.28906250e-01, -1.49414062e-01, 6.93359375e-02, -1.72851562e-01,
9.22851562e-02, 1.33056641e-02, -2.00195312e-01, -9.76562500e-02,
-1.65039062e-01, -2.46093750e-01, -2.35595703e-02, -2.11914062e-01,
1.84570312e-01, -1.85546875e-02, 2.16796875e-01, 5.05371094e-02,
2.02636719e-02, 4.25781250e-01, 1.28906250e-01, -2.77099609e-02,
1.29882812e-01, -1.15722656e-01, -2.05078125e-02, 1.49414062e-01,
7.81250000e-03, -2.05078125e-01, -8.05664062e-02, -2.67578125e-01,
-2.29492188e-02, -8.20312500e-02, 8.64257812e-02, 7.61718750e-02,
-3.66210938e-02, 5.22460938e-02, -1.22070312e-01, -1.44042969e-02,
-2.69531250e-01, 8.44726562e-02, -2.52685547e-02, -2.96630859e-02,
-1.68945312e-01, 1.93359375e-01, -1.08398438e-01, 1.94091797e-02,
-1.80664062e-01, 1.93359375e-01, -7.08007812e-02, 5.85937500e-02,
-1.01562500e-01, -1.31835938e-01, 7.51953125e-02, -7.66601562e-02,
3.37219238e-03, -8.59375000e-02, 1.25000000e-01, 2.92968750e-02,
1.70898438e-01, -9.37500000e-02, -1.09375000e-01, -2.50244141e-02,
2.11914062e-01, -4.44335938e-02, 6.12792969e-02, 2.62451172e-02,
-1.77734375e-01, 1.23046875e-01, -7.42187500e-02, -1.67968750e-01,
-1.08886719e-01, -9.04083252e-04, -7.37304688e-02, 5.49316406e-02,
6.03027344e-02, 8.39843750e-02, 9.17968750e-02, -1.32812500e-01,
1.22070312e-01, -8.78906250e-03, 1.19140625e-01, -1.94335938e-01,
-6.64062500e-02, -2.07031250e-01, 7.37304688e-02, 8.93554688e-02,
1.81884766e-02, -1.20605469e-01, -2.61230469e-02, 2.67333984e-02,
7.76367188e-02, -8.30078125e-02, 6.78710938e-02, -3.54003906e-02,
3.10546875e-01, -2.42919922e-02, -1.41601562e-01, -2.08007812e-01,
-4.57763672e-03, -6.54296875e-02, -4.95605469e-02, 2.22656250e-01,
1.53320312e-01, -1.38671875e-01, -5.24902344e-02, 4.24804688e-02,
-2.38281250e-01, 1.56250000e-01, 5.83648682e-04, -1.20605469e-01,
-9.22851562e-02, -4.44335938e-02, 3.61328125e-02, -1.86767578e-02,
-8.25195312e-02, -8.25195312e-02, -4.05273438e-02, 1.19018555e-02,
1.69921875e-01, -2.80761719e-02, 3.03649902e-03, 9.32617188e-02,
-8.49609375e-02, 1.57470703e-02, 7.03125000e-02, 1.62353516e-02,
-2.27050781e-02, 3.51562500e-02, 2.47070312e-01, -2.67333984e-02],
dtype=float32)
61. Word similarity
Tính cosine similarity của từ "United States" và "U.S."
model.similarity('United_States', 'U.S.')
0.73107743
62. Hiển thị top 10 có độ tương tự cao nhất
Trích xuất 10 từ có cosine similarity cao nhất với từ "United States" và giá trị cosine similarity của chúng.
model.most_similar('United_States', topn=10)
[('Unites_States', 0.7877248525619507),
('Untied_States', 0.7541370391845703),
('United_Sates', 0.74007248878479),
('U.S.', 0.7310774326324463),
('theUnited_States', 0.6404393911361694),
('America', 0.6178410053253174),
('UnitedStates', 0.6167312264442444),
('Europe', 0.6132988929748535),
('countries', 0.6044804453849792),
('Canada', 0.6019070148468018)]
63. Anology theo tính chất của phép cộng
Lấy word vector của từ "Spain" trừ đi vector của từ "Madrid", cộng vào vector của từ "Athens", đưa ra 10 từ có độ tương tự cao nhất với vector thu được cùng với độ tương tự của chúng.
model.most_similar(positive=['Spain', 'Athens'], negative=['Madrid'], topn=10)
[('Greece', 0.6898481249809265),
('Aristeidis_Grigoriadis', 0.5606848001480103),
('Ioannis_Drymonakos', 0.5552908778190613),
('Greeks', 0.545068621635437),
('Ioannis_Christou', 0.5400862693786621),
('Hrysopiyi_Devetzi', 0.5248444676399231),
('Heraklio', 0.5207759737968445),
('Athens_Greece', 0.516880989074707),
('Lithuania', 0.5166866183280945),
('Iraklion', 0.5146791934967041)]
64. Thực nghiệm trên dữ liệu Analogy
Tải xuống dữ liệu đánh giá cho bài toán Word Analogy, tính vec(từ ở cột thứ hai) - vec(từ ở cột đầu tiên) + vec(từ ở cột thứ ba) và tìm từ có độ tương tự cao nhất với vectơ thu được cùng với giá trị của độ tương tự. Viết thêm từ được tìm ra và độ tương tự vào cuối mỗi ví dụ.
# Tải xuống dữ liệu
!wget http://download.tensorflow.org/data/questions-words.txt
# Kiểm tra 10 dòng đầu tiên
!head -10 questions-words.txt
: capital-common-countries
Athens Greece Baghdad Iraq
Athens Greece Bangkok Thailand
Athens Greece Beijing China
Athens Greece Berlin Germany
Athens Greece Bern Switzerland
Athens Greece Cairo Egypt
Athens Greece Canberra Australia
Athens Greece Hanoi Vietnam
Athens Greece Havana Cuba
with open('./questions-words.txt', 'r') as f1, open('./questions-words-add.txt', 'w') as f2:
for line in f1: Đọc từng dòng từ # f1, thêm từ mong muốn và từ tương tự, rồi viết vào f2
line = line.split()
if line[0] == ':':
category = line[1]
print(category)
else:
word, cos = model.most_similar(positive=[line[1], line[2]], negative=[line[0]], topn=1)[0]
f2.write(' '.join([category] + line + [word, str(cos) + '\n']))
capital-common-countries
capital-world
currency
city-in-state
family
gram1-adjective-to-adverb
gram2-opposite
gram3-comparative
gram4-superlative
gram5-present-participle
gram6-nationality-adjective
gram7-past-tense
gram8-plural
gram9-plural-verbs
!head -10 questions-words-add.txt
capital-common-countries Athens Greece Baghdad Iraq Iraqi 0.6351870894432068
capital-common-countries Athens Greece Bangkok Thailand Thailand 0.7137669324874878
capital-common-countries Athens Greece Beijing China China 0.7235777974128723
capital-common-countries Athens Greece Berlin Germany Germany 0.6734622120857239
capital-common-countries Athens Greece Bern Switzerland Switzerland 0.4919748306274414
capital-common-countries Athens Greece Cairo Egypt Egypt 0.7527809739112854
capital-common-countries Athens Greece Canberra Australia Australia 0.583732545375824
capital-common-countries Athens Greece Hanoi Vietnam Viet_Nam 0.6276341676712036
capital-common-countries Athens Greece Havana Cuba Cuba 0.6460992097854614
capital-common-countries Athens Greece Helsinki Finland Finland 0.6899983882904053
65. Tính độ chính xác trên task Word Analogy
Sử dụng kết quả của bài 64, tính độ chính của semantic analogy và syntactic analogy.
with open('./questions-words-add.txt', 'r') as f:
sem_cnt = 0
sem_cor = 0
syn_cnt = 0
syn_cor = 0
for line in f:
line = line.split()
if not line[0].startswith('gram'):
sem_cnt += 1
if line[4] == line[5]:
sem_cor += 1
else:
syn_cnt += 1
if line[4] == line[5]:
syn_cor += 1
print(f'Tỷ lệ câu trả lời đúng semantic analogy: {sem_cor/sem_cnt:.3f}')
print(f'Tỷ lệ câu trả lời đúng syntactic analogy: {syn_cor/syn_cnt:.3f}')
Tỷ lệ câu trả lời đúng semantic analogy: 0.731
Tỷ lệ câu trả lời đúng syntactic analogy: 0.740
66. Đánh giá trên tập dữ liệu WordSimilarity-353
Download tập dữ liệu đánh giá The WordSimilarity-353 Test Collection, hãy tính độ tương quan Spearman giữa xếp hạng độ tương tự được tính toán dựa trên word vectors và xếp hạng được đoán định bởi con người.
!wget http://www.gabrilovich.com/resources/data/wordsim353/wordsim353.zip
!unzip wordsim353.zip
!head -10 './combined.csv'
Word 1,Word 2,Human (mean)
love,sex,6.77
tiger,cat,7.35
tiger,tiger,10.00
book,paper,7.46
computer,keyboard,7.62
computer,internet,7.58
plane,car,5.77
train,car,6.31
telephone,communication,7.50
ws353 = []
with open('./combined.csv', 'r') as f:
next(f)
for line in f: # Đọc từng dòng và tính toán vectơ từ và độ tương tự
line = [s.strip() for s in line.split(',')]
line.append(model.similarity(line[0], line[1]))
ws353.append(line)
# Xác nhận
for i in range(5):
print(ws353[i])
['love', 'sex', '6.77', 0.2639377]
['tiger', 'cat', '7.35', 0.5172962]
['tiger', 'tiger', '10.00', 0.99999994]
['book', 'paper', '7.46', 0.3634626]
['computer', 'keyboard', '7.62', 0.39639163]
import numpy as np
from scipy.stats import spearmanr
# Tính toán hệ số tương quan của Spearman
human = np.array(ws353).T[2]
w2v = np.array(ws353).T[3]
correlation, pvalue = spearmanr(human, w2v)
print(f'Hệ số tương quan Spearman: {correlation:.3f}')
Hệ số tương quan Spearman: 0.685
67. k-means clustering
Trích xuất các word vectors của các word liên quan đến tên quốc gia, sau đó thực hiện k-means clustering với số cluster k=5.
# Điều tra tên quốc gia
countries = set()
with open('./questions-words-add.txt') as f:
for line in f:
line = line.split()
if line[0] in ['capital-common-countries', 'capital-world']:
countries.add(line[2])
elif line[0] in ['currency', 'gram6-nationality-adjective']:
countries.add(line[1])
countries = list(countries)
# Nhận vector từ
countries_vec = [model[country] for country in countries]
from sklearn.cluster import KMeans
# Phân cụm k-means
kmeans = KMeans(n_clusters=5)
kmeans.fit(countries_vec)
for i in range(5):
cluster = np.where(kmeans.labels_ == i)[0]
print('cluster', i)
print(', '.join([countries[k] for k in cluster]))
cluster 0
Taiwan, Afghanistan, Iraq, Lebanon, Indonesia, Turkey, Egypt, Libya, Syria, Korea, China, Nepal, Cambodia, India, Bhutan, Qatar, Laos, Malaysia, Iran, Vietnam, Oman, Bahrain, Pakistan, Thailand, Bangladesh, Morocco, Jordan, Israel
cluster 1
Madagascar, Uganda, Botswana, Guinea, Malawi, Tunisia, Nigeria, Mauritania, Kenya, Zambia, Algeria, Mozambique, Ghana, Niger, Somalia, Angola, Mali, Senegal, Sudan, Zimbabwe, Gambia, Eritrea, Liberia, Burundi, Gabon, Rwanda, Namibia
cluster 2
Suriname, Uruguay, Tuvalu, Nicaragua, Colombia, Belize, Venezuela, Ecuador, Fiji, Peru, Guyana, Jamaica, Brazil, Honduras, Samoa, Bahamas, Dominica, Philippines, Cuba, Chile, Mexico, Argentina
cluster 3
Netherlands, Sweden, USA, Ireland, Canada, Spain, Malta, Greenland, Europe, Greece, France, Austria, Norway, Finland, Australia, Japan, Iceland, England, Italy, Denmark, Belgium, Switzerland, Germany, Portugal, Liechtenstein
cluster 4
Croatia, Belarus, Uzbekistan, Latvia, Tajikistan, Slovakia, Ukraine, Hungary, Albania, Poland, Montenegro, Georgia, Russia, Kyrgyzstan, Armenia, Romania, Cyprus, Lithuania, Azerbaijan, Serbia, Slovenia, Turkmenistan, Moldova, Bulgaria, Estonia, Kazakhstan, Macedonia
68. Clustering theo phương pháp Ward
Trích xuất các word vectors của các word liên quan đến tên quốc gia, thực hiện hierarchical clustering bằng phương pháp Ward. Visualize kết quả clustering dưới dạng dendogram.
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
plt.figure(figsize=(15, 5))
Z = linkage(countries_vec, method='ward')
dendrogram(Z, labels=countries)
plt.show()
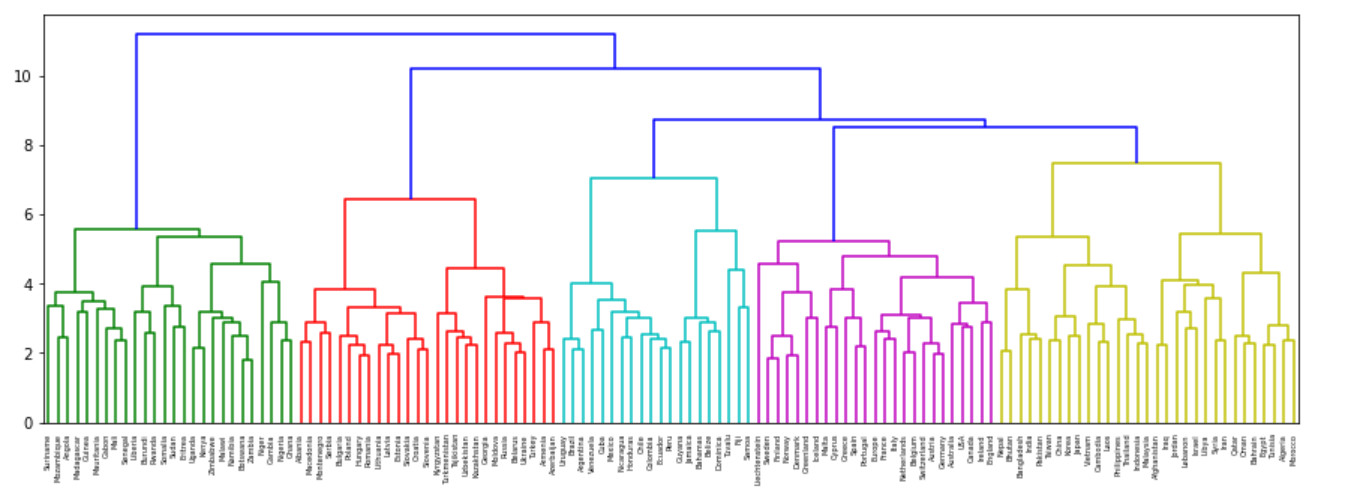
69. Visualize bằng t-SNE
Visualize không gian vector của các word liên quan đến tên quốc gia bằng t-SNE.
!pip install bhtsne
import bhtsne
embedded = bhtsne.tsne(np.array(countries_vec).astype(np.float64), dimensions=2, rand_seed=123)
plt.figure(figsize=(10, 10))
plt.scatter(np.array(embedded).T[0], np.array(embedded).T[1])
for (x, y), name in zip(embedded, countries):
plt.annotate(name, (x, y))
plt.show()
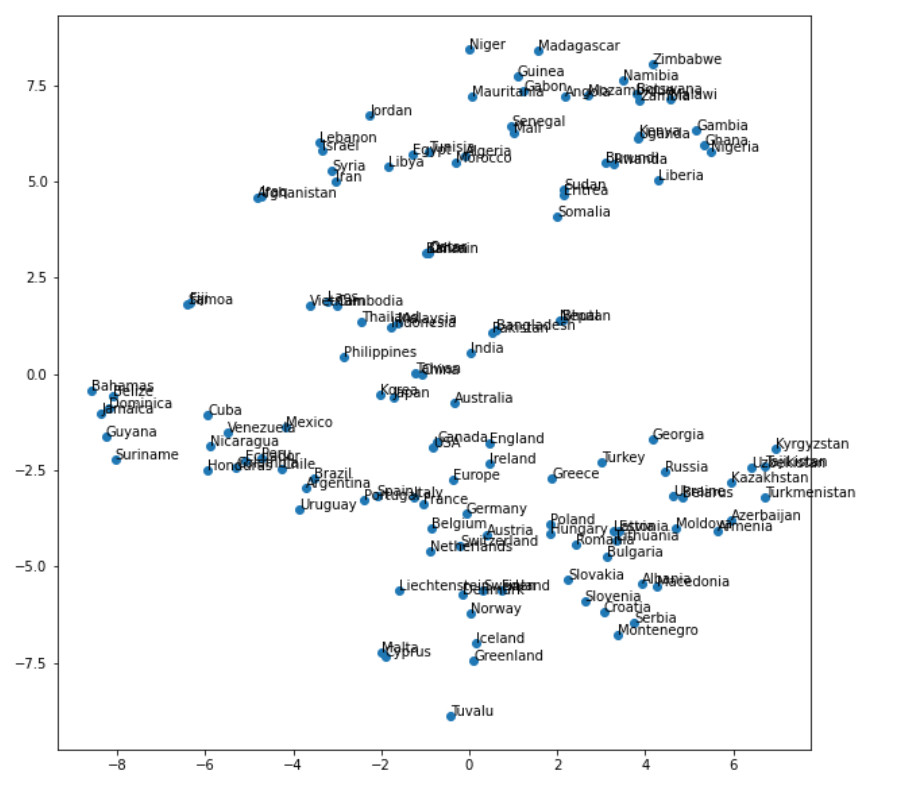
Chương 8: Neural Networks
Cài đặt mô hình phân loại bằng mạng neural cho bài toán phân loại các bài báo đã làm trong chương 6. Sử dụng các nền tảng học máy như PyTorch, TensorFlow hoặc Chainer trong chương này.
70. Sử dụng tổng của các word vectors làm features
Chúng ta muốn chuyển đổi dữ liệu train, valid và test được xây dựng trong bài tập 50 thành ma trận và vectơ.
Ví dụ, đối với dữ liệu train, chúng ta muốn tạo một ma trận X gồm các vectơ đặc trưng của tất cả các example và ma trận (vectơ) Y gồm các nhãn của các example.
Ở đây n là số lượng các example trong dữ liệu train, và lần lượt biểu diễn vectơ đặc trưng và nhãn của ví dụ thứ . Chú ý rằng, chúng ta sẽ dùng 4 nhãn "business", "science and technology", "entertainment", "health". Nếu sử dụng kí hiệu để biểu diễn các số tự nhiên nhỏ hơn 4 (bao gồm cả 0), thì chúng ta có thể biểu diễn nhãn Sau đây, chúng ta sẽ biểu diễn số lớp là L (trong bài toán phân loại hiện tại thì L = 4).
Vector đặc trưng của example thứ i sẽ được tính bởi công thức sau.
Ở đây, example thứ i được cấu thành từ một dãy token , là word vector (số chiều là d) tương ứng với token w. Tức là, title của bài báo của điểm dữ liệu thứ i được biểu diễn bằng vector sẽ được tính bằng cách lấy trung bình các word vector của các token nằm trong title đó. Trong chương này, chúng ta có thể sử dụng bộ word vector đã tải về trong bài tập 60. Vì chúng ta dùng các word vector với số chiều 300 nên d=300.
Chúng ta định nghĩa nhãn của example thứ i như sau.
Ngoài ra, nếu tên category và số biểu diễn nhãn tương ứng 1-1, bạn không nhất thiết phải sử dụng công thức ở trên.
Dựa vào phương pháp ở trên, hãy tạo các ma trận - vector dưới đây rồi lưu vào file.
Ma trận feature của tập dữ liệu train:
Vector label của tập dữ liệu train:
Ma trận featture của tập dữ liệu kiểm chứng:
Vector label của tập dữ liệu kiểm chứng:
Ma trận feature của tập dữ liệu test:
Vector label của tập dữ liệu test:
Ở đây, tương ứng là số lượng example trong tập dữ liệu train, valid và test.
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip
!unzip NewsAggregatorDataset.zip
!wc -l ./newsCorpora.csv
422937 ./newsCorpora.csv
!head -10 ./newsCorpora.csv
1 Fed official says weak data caused by weather, should not slow taper http://www.latimes.com/business/money/la-fi-mo-federal-reserve-plosser-stimulus-economy-20140310,0,1312750.story\?track=rss Los Angeles Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.latimes.com 1394470370698
2 Fed's Charles Plosser sees high bar for change in pace of tapering http://www.livemint.com/Politics/H2EvwJSK2VE6OF7iK1g3PP/Feds-Charles-Plosser-sees-high-bar-for-change-in-pace-of-ta.html Livemint b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.livemint.com 1394470371207
3 US open: Stocks fall after Fed official hints at accelerated tapering http://www.ifamagazine.com/news/us-open-stocks-fall-after-fed-official-hints-at-accelerated-tapering-294436 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371550
4 Fed risks falling 'behind the curve', Charles Plosser says http://www.ifamagazine.com/news/fed-risks-falling-behind-the-curve-charles-plosser-says-294430 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371793
5 Fed's Plosser: Nasty Weather Has Curbed Job Growth http://www.moneynews.com/Economy/federal-reserve-charles-plosser-weather-job-growth/2014/03/10/id/557011 Moneynews b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.moneynews.com 1394470372027
6 Plosser: Fed May Have to Accelerate Tapering Pace http://www.nasdaq.com/article/plosser-fed-may-have-to-accelerate-tapering-pace-20140310-00371 NASDAQ b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.nasdaq.com 1394470372212
7 Fed's Plosser: Taper pace may be too slow http://www.marketwatch.com/story/feds-plosser-taper-pace-may-be-too-slow-2014-03-10\?reflink=MW_news_stmp MarketWatch b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.marketwatch.com 1394470372405
8 Fed's Plosser expects US unemployment to fall to 6.2% by the end of 2014 http://www.fxstreet.com/news/forex-news/article.aspx\?storyid=23285020-b1b5-47ed-a8c4-96124bb91a39 FXstreet.com b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.fxstreet.com 1394470372615
9 US jobs growth last month hit by weather:Fed President Charles Plosser http://economictimes.indiatimes.com/news/international/business/us-jobs-growth-last-month-hit-by-weatherfed-president-charles-plosser/articleshow/31788000.cms Economic Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM economictimes.indiatimes.com 1394470372792
10 ECB unlikely to end sterilisation of SMP purchases - traders http://www.iii.co.uk/news-opinion/reuters/news/152615 Interactive Investor b dPhGU51DcrolUIMxbRm0InaHGA2XM www.iii.co.uk 1394470501265
!sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csv
import pandas as pd
from sklearn.model_selection import train_test_split
# Đọc dữ liệu
df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP'])
# Trích xuất dữ liệu
df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']]
# Phân chia dữ liệu
train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY'])
valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY'])
# Xác nhận số trường hợp
print('[Dữ liệu train]')
print(train['CATEGORY'].value_counts())
print('[Dữ liệu xác minh]')
print(valid['CATEGORY'].value_counts())
print('[Dữ liệu đánh giá]')
print(test['CATEGORY'].value_counts())
[Dữ liệu train]
b 4501
e 4235
t 1220
m 728
Name: CATEGORY, dtype: int64
[Dữ liệu xác minh]
b 563
e 529
t 153
m 91
Name: CATEGORY, dtype: int64
[Dữ liệu đánh giá]
b 563
e 530
t 152
m 91
Name: CATEGORY, dtype: int64
train.to_csv('train.tsv', index=False, sep='\t', header=False)
valid.to_csv('valid.tsv', index=False, sep='\t', header=False)
test.to_csv('test.tsv', index=False, sep='\t', header=False)
import gdown
from gensim.models import KeyedVectors
# Tải xuống vector từ đã học
url = "https://drive.google.com/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM"
output = 'GoogleNews-vectors-negative300.bin.gz'
gdown.download(url, output, quiet=True)
#Load tệp tải xuống
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True)
import string
import torch
def transform_w2v(text):
table = str.maketrans(string.punctuation, ' '*len(string.punctuation))
words = text.translate(table).split() Sau khi thay dấu # bằng dấu cách, hãy chia dấu cách cho dấu cách và liệt kê.
vec = [model[word] for word in words if word in model] # Vectơ hóa từng từ một
return torch.tensor(sum(vec) / len(vec)) # Chuyển đổi vectơ trung bình sang loại và đầu ra Tensor
# Tạo vectơ đối tượng
X_train = torch.stack([transform_w2v(text) for text in train['TITLE']])
X_valid = torch.stack([transform_w2v(text) for text in valid['TITLE']])
X_test = torch.stack([transform_w2v(text) for text in test['TITLE']])
print(X_train.size())
print(X_train)
torch.Size([10684, 300])
tensor([[ 0.0837, 0.0056, 0.0068, ..., 0.0751, 0.0433, -0.0868],
[ 0.0272, 0.0266, -0.0947, ..., -0.1046, -0.0489, -0.0092],
[ 0.0577, -0.0159, -0.0780, ..., -0.0421, 0.1229, 0.0876],
...,
[ 0.0392, -0.0052, 0.0686, ..., -0.0175, 0.0061, -0.0224],
[ 0.0798, 0.1017, 0.1066, ..., -0.0752, 0.0623, 0.1138],
[ 0.1664, 0.0451, 0.0508, ..., -0.0531, -0.0183, -0.0039]])
# Tạo vectơ nhãn
category_dict = {'b': 0, 't': 1, 'e':2, 'm':3}
y_train = torch.LongTensor(train['CATEGORY'].map(lambda x: category_dict[x]).values)
y_valid = torch.LongTensor(valid['CATEGORY'].map(lambda x: category_dict[x]).values)
y_test = torch.LongTensor(test['CATEGORY'].map(lambda x: category_dict[x]).values)
print(y_train.size())
print(y_train)
torch.Size([10684])
tensor([0, 1, 3, ..., 0, 3, 2])
torch.save(X_train, 'X_train.pt')
torch.save(X_valid, 'X_valid.pt')
torch.save(X_test, 'X_test.pt')
torch.save(y_train, 'y_train.pt')
torch.save(y_valid, 'y_valid.pt')
torch.save(y_test, 'y_test.pt')
71. Dự đoán dùng mạng neural đơn tầng
Đọc vào ma trận/vector đã lưu ở bài tập 70, hãy thực hiện tính toán dưới đây trên dữ liệu train.
Ở đây, softmax là kí hiệu của hàm softmax, là ma trận với các vector đặc trưng xếp theo hàng dọc.
Ma trận à ma trận trọng số của mạng neural 1 tầng ẩn, ở đây bạn có thể khởi tạo ngẫu nhiên giá trị của ma trận (từ bài 73 trở đi chúng ta sẽ học ma trận trọng số này). Ngoài ra, là vector biểu diễn xác suất example thuộc về các lớp khi dùng ma trận chưa được học để phân loại. Tương tự, là ma trận biểu diễn xác xuất các example thuộc về các lớp.
from torch import nn
torch.manual_seed(0)
class SLPNet(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.fc = nn.Linear(input_size, output_size, bias=False) #Linear (số thứ nguyên đầu vào, số thứ nguyên đầu ra)
nn.init.normal_(self.fc.weight, 0.0, 1.0) # Khởi tạo trọng lượng bằng số ngẫu nhiên bình thường
def forward(self, x):
x = self.fc(x)
return x
model = SLPNet(300, 4)
y_hat_1 = torch.softmax(model.forward(X_train[:1]), dim=-1)
print(y_hat_1)
tensor([[0.4273, 0.0958, 0.2492, 0.2277]], grad_fn=<SoftmaxBackward>)
Y_hat = torch.softmax(model.forward(X_train[:4]), dim=-1)
print(Y_hat)
tensor([[0.4273, 0.0958, 0.2492, 0.2277],
[0.2445, 0.2431, 0.0197, 0.4927],
[0.7853, 0.1132, 0.0291, 0.0724],
[0.5279, 0.2319, 0.0873, 0.1529]], grad_fn=<SoftmaxBackward>)
72. Tính loss và gradient
Hãy tính hàm cross entropy loss và gradient theo ma trận đối với example và tập các example của tập dữ liệu huấn luyện. Hơn nữa, hàm loss đối với example được tính bởi công thức sau đây.
Thật ra, hàm cross-entropy loss đối với một tập các example sẽ lấy trung bình cộng của hàm loss của các example trong tập dữ liệu đó.
criterion = nn.CrossEntropyLoss()
l_1 = criterion(model.forward(X_train[:1]), y_train[:1]) # Vectơ đầu vào là giá trị trước softmax
model.zero_grad() # Khởi tạo gradient thành 0
l_1.backward() # Tính toán độ gradient
print(f'loss: {l_1:.4f}')
print(f'gradient:\n{model.fc.weight.grad}')
loss: 0.8503
gradient:
tensor([[-0.0479, -0.0032, -0.0039, ..., -0.0430, -0.0248, 0.0497],
[ 0.0080, 0.0005, 0.0007, ..., 0.0072, 0.0041, -0.0083],
[ 0.0208, 0.0014, 0.0017, ..., 0.0187, 0.0108, -0.0216],
[ 0.0190, 0.0013, 0.0016, ..., 0.0171, 0.0099, -0.0198]])
l = criterion(model.forward(X_train[:4]), y_train[:4])
model.zero_grad()
l.backward()
print(f'loss: {l:.4f}')
print(f'gradient:\n{model.fc.weight.grad}')
loss: 1.8321
gradient:
tensor([[-0.0063, 0.0042, -0.0139, ..., -0.0272, 0.0201, 0.0263],
[-0.0047, -0.0025, 0.0195, ..., 0.0196, 0.0160, 0.0009],
[ 0.0184, -0.0110, -0.0148, ..., 0.0070, -0.0055, -0.0001],
[-0.0074, 0.0092, 0.0092, ..., 0.0006, -0.0306, -0.0272]])
73. Training với thuật toán Stochastic Gradient Descent
Sử dụng thuật toán Stochastic Gradient Descent (SGD), hãy học ma trận . Thêm nữa, bước training có thể được cho kết thúc bằng một tiêu chuẩn thích hợp (ví dụ "kết thúc khi đã qua 100 epoch").
from torch.utils.data import Dataset
class CreateDataset(Dataset):
def __init__(self, X, y): # Chỉ định các thành phần của dataset
self.X = X
self.y = y
def __len__(self): # Chỉ định giá trị được trả về bởi len(dataset)
return len(self.y)
def __getitem__(self, idx): # Chỉ định giá trị được trả về bởi dataset[idx]
if isinstance(idx, torch.Tensor):
idx = idx.tolist()
return [self.X[idx], self.y[idx]]
from torch.utils.data import DataLoader
dataset_train = CreateDataset(X_train, y_train)
dataset_valid = CreateDataset(X_valid, y_valid)
dataset_test = CreateDataset(X_test, y_test)
dataloader_train = DataLoader(dataset_train, batch_size=1, shuffle=True)
dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False)
dataloader_test = DataLoader(dataset_test, batch_size=len(dataset_test), shuffle=False)
print(len(dataset_train))
print(next(iter(dataloader_train)))
10684
[tensor([[-2.2791e-02, -1.6650e-02, 1.2573e-02, 1.1694e-02, -2.0509e-02,
-4.1607e-02, -1.1132e-01, -4.7964e-02, 7.6147e-02, 9.4415e-02,
-3.7549e-02, 7.2437e-02, -3.8168e-02, 7.9443e-02, -6.0207e-02,
-5.1074e-02, -1.8954e-02, 7.6978e-02, 8.1055e-02, -8.3789e-02,
-1.3208e-02, 2.0891e-01, 9.6887e-02, -2.3356e-02, -7.3456e-02,
5.9668e-02, -4.8009e-02, 8.0090e-02, 2.8123e-02, -1.6791e-02,
2.0227e-02, -9.6387e-02, 1.6510e-02, -1.6281e-02, -4.0601e-02,
-8.2489e-02, 9.8975e-02, 1.4099e-03, 1.4362e-02, 3.9368e-02,
7.6392e-02, -1.3135e-01, 1.3572e-01, -1.4496e-03, -8.1097e-02,
-6.5753e-02, -9.6622e-02, 2.0679e-02, 4.8145e-02, 5.0012e-02,
7.2842e-02, 4.8761e-02, 4.9164e-02, 1.1853e-01, 2.7307e-02,
-6.8723e-02, 4.0675e-02, -2.6984e-02, -1.6510e-02, -1.6882e-01,
5.8417e-02, -2.1912e-02, -4.8096e-02, -9.4360e-02, -6.9186e-02,
-1.2361e-02, -7.6489e-02, 5.1843e-02, 1.5080e-01, 5.7861e-03,
-6.3660e-02, -9.0894e-02, 1.1075e-01, 3.5229e-02, -1.0220e-01,
-2.4133e-02, 1.8951e-02, 1.0651e-01, 1.5167e-02, 8.7891e-03,
-5.8649e-02, -4.8902e-02, -1.7447e-02, -5.0873e-03, 2.0083e-02,
-3.3643e-02, -1.1077e-01, 9.6948e-02, -4.5068e-02, -4.8102e-02,
1.9116e-02, -1.7224e-02, -1.0402e-01, -4.5465e-02, -3.8379e-02,
-1.8384e-02, 6.0464e-02, -1.7932e-02, 8.9215e-02, -6.3168e-02,
1.6414e-02, -4.4244e-02, 6.6852e-02, 8.0658e-03, -7.7148e-02,
-1.0146e-01, -1.1623e-01, 1.1017e-02, -2.3859e-02, -5.6921e-02,
-8.0200e-03, 3.2812e-02, -2.6733e-02, -6.9550e-03, 8.5193e-02,
-1.1182e-02, -1.3623e-02, -4.4067e-02, 1.0166e-01, 9.5972e-02,
1.8344e-02, 5.8070e-02, 4.4479e-04, 5.7736e-02, 8.2104e-02,
-4.7461e-02, 1.7114e-02, -2.7600e-02, -8.2092e-03, 6.6895e-02,
3.8300e-02, -1.7280e-01, 1.5320e-02, -9.0527e-02, -5.0513e-02,
-9.0625e-02, -3.4372e-02, 4.9023e-02, -1.0402e-01, 5.3085e-02,
1.6299e-01, -2.0200e-01, 6.9128e-02, -3.4766e-02, -1.2520e-01,
4.7406e-02, 3.7939e-02, -2.7258e-02, 4.7699e-03, -4.1489e-02,
1.5836e-01, -3.4470e-02, 7.9187e-02, 7.0186e-02, -9.9365e-03,
5.1636e-03, -7.1176e-02, -6.1713e-02, -1.4331e-02, -7.9578e-02,
2.8979e-02, 4.8320e-02, 6.1710e-02, 6.6895e-03, 3.5571e-02,
-2.9993e-02, 1.0642e-01, 7.7972e-03, 3.1024e-02, -3.0566e-02,
-1.3335e-01, 4.5648e-02, 2.7258e-02, -1.3228e-01, -3.9993e-03,
-4.0796e-02, -1.0620e-02, 2.3071e-02, 1.1028e-01, -7.1956e-02,
-1.2183e-01, -1.0478e-01, -5.9741e-02, -1.5576e-02, -5.0122e-02,
-1.0491e-01, 6.6578e-02, 8.7109e-02, 7.7832e-02, 7.1664e-02,
-1.4240e-02, 1.6156e-02, 9.9219e-02, 3.7555e-02, -1.4541e-01,
7.7380e-02, -7.4424e-02, -1.5622e-02, -7.6538e-02, -1.1675e-01,
-7.0117e-02, -2.4982e-02, -2.1033e-02, -1.0903e-01, -7.1951e-02,
-7.8564e-02, -3.1067e-02, -1.0606e-02, 9.1476e-02, -1.1772e-01,
-7.9239e-02, 1.0401e-01, -5.2237e-02, 5.0278e-02, -9.8535e-02,
1.4659e-02, 5.7626e-02, -3.9384e-02, -2.1252e-01, 4.3774e-02,
3.9404e-02, 9.2145e-02, -9.3225e-02, -4.1455e-02, -1.4404e-02,
5.6091e-03, 8.7646e-03, -3.4631e-02, -1.5869e-03, 3.8266e-02,
-7.5806e-03, 2.2644e-02, 9.0625e-02, -8.6884e-03, -2.5506e-02,
1.8097e-03, 1.1675e-01, -5.1315e-02, 4.1077e-02, -5.5695e-03,
2.9001e-02, 3.6060e-02, -8.0099e-02, -8.0518e-02, -9.3018e-03,
-3.3798e-02, 1.8066e-02, 9.7656e-03, 5.8420e-02, -1.0171e-01,
-5.9680e-02, 7.2296e-02, -4.7632e-02, 4.5984e-02, -6.7035e-02,
-5.9448e-02, 6.5326e-02, 9.1699e-02, 3.5828e-02, -3.7921e-02,
-1.2726e-03, 4.9103e-02, 2.4626e-02, 8.0011e-02, -1.2207e-05,
1.6797e-01, -6.0141e-02, -1.0533e-01, 1.0718e-02, 4.2593e-02,
-3.4094e-02, 8.3630e-02, 3.6023e-02, -4.1527e-02, 4.7495e-02,
2.9892e-03, -9.2068e-03, 2.6147e-02, -3.7276e-02, 8.0615e-02,
-8.7317e-02, -1.7491e-02, 2.1057e-02, 1.0767e-01, 4.3916e-02,
-3.1616e-03, -1.0800e-01, 2.4817e-02, 1.6101e-02, 5.0292e-02,
-8.6255e-02, -5.5252e-03, -4.6820e-02, 5.6238e-02, 8.2507e-02,
5.3406e-03, 8.2825e-03, 2.1946e-02, 2.3987e-03, -4.1766e-02]]), tensor([0])]
# Định nghĩa mô hình
model = SLPNet(300, 4)
# Định nghĩa của hàm Loss
criterion = nn.CrossEntropyLoss()
# Định nghĩa của trình tối ưu hóa
optimizer = torch.optim.SGD(model.parameters(), lr=1e-1)
num_epochs = 10
for epoch in range(num_epochs):
# Đặt thành chế độ train
model.train()
loss_train = 0.0
for i, (inputs, labels) in enumerate(dataloader_train):
# Khởi tạo gradient thành 0
optimizer.zero_grad()
# Truyền phát mượt mà + phát ngược lỗi + cập nhật lại
outputs = model.forward(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Ghi nhận loss
loss_train += loss.item()
# Tính toán tổn thất trung bình theo lô
loss_train = loss_train / i
Tính toán mất mát dữ liệu #Validation
model.eval()
with torch.no_grad():
inputs, labels = next(iter(dataloader_valid))
outputs = model.forward(inputs)
loss_valid = criterion(outputs, labels)
# Nhật ký đầu ra
print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, loss_valid: {loss_valid:.4f}')
epoch: 1, loss_train: 0.4686, loss_valid: 0.3738
epoch: 2, loss_train: 0.3159, loss_valid: 0.3349
epoch: 3, loss_train: 0.2846, loss_valid: 0.3248
epoch: 4, loss_train: 0.2689, loss_valid: 0.3194
epoch: 5, loss_train: 0.2580, loss_valid: 0.3094
epoch: 6, loss_train: 0.2503, loss_valid: 0.3089
epoch: 7, loss_train: 0.2437, loss_valid: 0.3068
epoch: 8, loss_train: 0.2401, loss_valid: 0.3083
epoch: 9, loss_train: 0.2358, loss_valid: 0.3077
epoch: 10, loss_train: 0.2338, loss_valid: 0.3052
74. Tính độ chính xác
Khi sử dụng ma trận trọng số đã tìm được ở bài tập 73 để phân loại các ví dụ của tập train và tập tập test, hãy tính độ chính xác trên các tập dữ liệu.
def calculate_accuracy(model, X, y):
model.eval()
with torch.no_grad():
outputs = model(X)
pred = torch.argmax(outputs, dim=-1)
return (pred == y).sum().item() / len(y)
# Xác nhận tỷ lệ câu trả lời đúng
acc_train = calculate_accuracy(model, X_train, y_train)
acc_test = calculate_accuracy(model, X_test, y_test)
print(f'Tỷ lệ câu trả lời đúng (dữ liệu train)):{acc_train:.3f}')
print(f'Tỷ lệ trả lời đúng (dữ liệu test):{acc_test:.3f}')
# Tỷ lệ câu trả lời đúng (dữ liệu train):0.925
# Tỷ lệ trả lời đúng (dữ liệu test):0.902
75. Plot loss và độ chính xác
Sửa code của bài 73, xác nhận trạng thái của quá trình training bằng cách sau mỗi lần kết thúc việc cập nhật tham số trong mỗi epoch, vẽ đồ thị của giá trị hàm loss, accuracy trên tập train và tập valid.
76. Checkpoint
Cải biến code của bài tập 75, mỗi khi kết thúc việc cập nhật tham số trong mỗi epoch, lưu lại checkpoint (giá trị của parameter (chẳng hạn ma trận trong số) trong lúc training và trạng thái bên trọng của thuật toán tối ưu hóa) vào file.
77. Sử dụng mini-batch
Sửa code của bài 76, hãy tính toán giá trị hàm loss, gradient cho mỗi B example và cập nhật giá trị của ma trận trọng số (mini-batching). Thay đổi giá trị của B với các giá trị 1, 2, 4, 8,... và so sánh thời gian học cần thiết cho mỗi epoch.
78. Train trên GPU
Cải biến code của bài 77 và thực hiện train trên GPU.
79. Mạng neural nhiều tầng
Cải biến code của bài tập 78, hãy thay đổi kiến trúc của mạng neural bằng việc thêm vào bias term và thêm layer, hãy tạo một bộ phân lớp có hiệu quả cao.
Chương 9: RNN, CNN
80. Biến đổi thành số ID
Chúng ta muốn gán cho mỗi từ trong dữ liệu huấn luyện chúng ta đã tạo ra trong bài tập 51 một số ID duy nhất. Hãy gán số ID cho các từ xuất hiện 2 lần trở lên trong dữ liệu huấn luyện bằng phương pháp: từ xuất hiện nhiều nhất được gán ID bằng 1, từ xuất hiện nhiều thứ 2 được gán ID bằng 2,... Sau đó, hãy cài đặt hàm trả về một dãy các ID cho một chuỗi các từ cho trước. Ngoài ra, tất cả các từ có tần suất xuất hiện ít hơn 2 (trong dữ liệu train) được gán ID bằng 0.
81. Dự đoán bằng mô hình RNN
Cho trước một chuỗi từ được biểu diễn bằng các số ID. Trong đó, T là độ dài của chuỗi từ, là biểu diễn one-hot của ID tương ứng với từ (V là tổng số từ). Cài đặt phương trình sau đây dưới dạng mô hình dự đoán nhãn y từ chuỗi từ x, sử dụng mạng neural hồi quy (RNN: Recurrent Neural Network).
Trong đó là kí hiệu của word embedding (hàm số biến đổi biểu diễn dạng one-hot của từ thành word vector), là vector của hidden state tại time step t, là RNN unit để tính toán hidden state tiếp theo từ đầu vào x và hidden state tại time step trước, là ma trận để dự đoán nhãn từ vector của hidden state, là bias term ( lần lượt là số chiều của word embedding, số chiều của hidden state và số lượng nhãn). Có rất nhiều kiến trúc khác nhau trong RNN unit và dưới đây là một mô hình cổ điển.
Trong đó, là tham số của RNN unit, g là hàm activation (chẳng hạn hàm tanh hay ReLU).
Chú ý rằng, trong bài tập này, chúng ta không huấn luyện các tham số mà nhãn y có thể được dự đoán bằng các tham số được khởi tạo ngẫu nhiên. Hãy chọn các giá trị phù hợp cho các hyperparameter như số chiều, ví dụ: (trong các bài tiếp theo chúng ta sẽ dùng cùng các hyperparameter đã thiết lập).
82. Huấn luyện bằng thuật toán Stochastic Gradient Descent
Sử dụng thuật toán SGD (Stochastic Gradient Descent), hãy huấn luyện mô hình đã tạo ra ở bài 81. Huấn luyện mô hình, đồng thời hiển thị giá trị của hàm loss và độ chính xác trên tập huấn luyện và tập test. Hãy kết thúc giải thuật với tiêu chuẩn thích hợp (ví dụ sau 10 epochs).
83. Mini-batching và huấn luyện trên GPU
Sửa code của bài 82, hãy tính toán giá trị hàm loss, gradient cho mỗi B example và huấn luyện mô hình (hãy chọn giá trị thích hợp cho B). Thêm nữa, hãy train mô hình trên GPU.
84. Áp dụng word embedding
Hãy khởi tạo word embedding bằng pre-trained word vector (chẳng hạn bộ pre-trained word vector được huấn luyện trên tập dữ liệu Google News (khoảng 100 tỉ từ)) và huấn luyện mạng neural.
85. Bidirection RNN - Mạng RNN nhiều tầng
Sử dụng forward RNN và backward RNN để encode text đầu vào và học mô hình.
Ở đây, lần lượt là các hidden state vector ở time step t, sinh ra bởi forward và backward RNN, là RNN unit để tính toán hidden state trước đó từ đầu vào x và hidden state h ở time step kế tiếp, là ma trận dự đoán các category từ hidden state vector, là bias term. Ngoài ra kí hiệu [a; b] biểu diễn vector tạo thành bằng cách concat các vector a và b.
86. Mạng neural tích chập (CNN)
Cho trước chuỗi các từ được biểu diễn bằng các số ID . Ở đây, T là độ dài của chuỗi từ, là biểu diễn dạng one-hot của số ID của từ (_V* là số lượng các từ). Sử dụng mạng neural tích chập (CNN: Convolutional Neural Network), cài đặt mô hình dự đoán nhãn y từ chuỗi các từ x.
Thêm nữa, cấu trúc mạng CNN được cho như ở dưới đây.
Số chiều của word embedding:
Filter size của convolution: 3 token
Kích thước của stride trong convolution: 1 token
Có sử dụng padding
Số chiều của vector của các time step sau convolution operator:
Sử dụng max pooling sau convolution layer, biểu diễn câu đầu vào bằng hidden state vector với số chiều
Vector đặc trưng tại time step t được tính bằng công thức sau.
Ở đây, là tham số của mạng CNN, g là hàm activation (chẳng hạn như hàm tanh hay ReLU), [a;b;c] là vector tạo thành bằng cách concat các vector a, b, c. Ngoài ra, lý do số cột của ma trận là là ma trận đó dùng để thực hiện biến đổi tuyến tính trên vector được tạo thành bằng cách concate word embedding vector của 3 token.
Max pooling lấy ra giá trị lớn nhất trên toàn bộ time step cho mỗi chiều của vector đặc trưng và tính ra vector biểu diễn text đầu vào. Nếu biểu diễn giá trị ở vị trí thứ _i* của c bằng c[i] thì Max Pooling được biểu diễn bằng công thức sau đây.
Cuối cùng, áp dụng biến đổi tuyến tính bằng ma trận và số hạng bias , sau đó là áp dụng hàm softmax trên vector đặc trưng _c* của text đầu vào để dự đoán nhãn y.
Chú ý rằng, trong bài tập này, chúng ta không học mô hình mà chỉ cần tính toán y bằng ma trận trọng số được khởi tạo ngẫu nhiên.
87. Huấn luyện mô hình CNN bằng thuật toán Stochastic Gradient Descent
Sử dụng thuật toán SGD (Stochastic Gradient Descent), hãy huấn luyện mô hình đã tạo ra ở bài 86. Huấn luyện mô hình, đồng thời hiển thị giá trị của hàm loss và độ chính xác trên tập huấn luyện và tập test. Hãy kết thúc giải thuật với tiêu chuẩn thích hợp (ví dụ sau 10 epochs).
88. Hyperparameter tuning
Sửa code của bài tập 85 và 87, thay đổi kiến trúc mạng và các hyperparameter để xây dựng một bộ phân loại văn bản có hiệu quả cao.
89. Transfer learning từ mô hình ngôn ngữ đã được pre-train
Lấy mô hình ngôn ngữ đã được huấn luyện trước (ví dụ BERT) làm xuất phát điểm, hãy xây dựng mô hình phân loại tiêu đề của các bài tin tức.
Chương 10: Machine Translation
Trong chương này, chúng ta sẽ sử dụng corpus song ngữ Nhật - Anh của The Kyoto Free Translation Task (KFTT) và huấn luyện mô hình dịch máy dùng mạng neural (neural machine translation). Khi tạo mô hình dịch máy dùng mạng neural, hãy dùng các công cụ có sẵn như fairseq, Hugging Face Transformers hay OpenNMT-py.
90. Chuẩn bị dữ liệu
Download dữ liệu dịch máy. Tạo dữ liệu train, dev và test và thực hiện tiền xử lý cần thiết như tokenization. Thực ra ở mức độ này, chúng ta sẽ sử dụng word (trong tiếng Anh) và morpheme (trong tiếng Nhật) như là đơn vị của token.
91. Huấn luyện mô hình dịch máy
Sử dụng dữ liệu đã chuẩn bị ở bài tập 90, hãy học mô hình dịch máy dùng mạng neural (có thể chọn mô hình mạng neural như Transformer hay LSTM).
92. Áp dụng mô hình dịch máy
Sử dụng mô hình dịch máy neural đã học ở bài tập 91, cài đặt chương trình dịch một câu tiếng Nhật cho trước (tùy ý) ra tiếng Anh.
93. Tính BLEU score
Để kiểm tra chất lượng của mô hình dịch máy neural đã học ở bài tập 91, tính điểm BLEU trên dữ liệu test.
94. Beam Search
Trong bước decode câu dịch bằng mô hình dịch máy neural đã học ở bài 91, hãy sử dụng thuật toán beam search. Thay đổi beam size từ 1 đến 100 và vẽ đồ thị thể hiện sự biến đổi của BLEU score trên tập dev.
95. Sử dụng subword
Thay đổi từ đơn vị của token từ word hoặc morpheme thành subword và thực hiện lại các thí nghiệm từ bài 91 đến bài 94.
96. Visualize quá trình training
Sử dụng công cụ chẳng hạn Tensorboard hãy visualize quá trình mô hình dịch máy neural được học. Hãy dùng giá trị của hàm loss và BLUE score trên tập train và giá trị hàm loss và BLEU score trên tập dev để quan sát khi visualize quá trình học model.
97. Tune hyper-parameters
Thay đổi mô hình mạng neural cùng với các hyper-parameters và tìm ra mô hình mạng và bộ hyper-parameters cho BLEU score cao nhất trên tập dữ liệu dev.
98. Domain adaptation
Sử dụng dữ liệu dịch máy Japanese-English Subtitle Corpus (JESC) hoặc JParaCrawl, thử tăng performance trên tập test của dữ liệu KFTT.
99. Tạo translation server
Tạo hệ thống demo trên nền Web hiển thị kết quả dịch khi người dùng nhập vào một câu muốn dịch.
Reference
Dịch từ tài liệu 言語処理 100 本ノック của lab Inui-Okazaki, đại học Tohoku, Nhật Bản. Người dịch: Phạm Quang Nhật Minh (minhpqn).
Tham khảo thêm phiên bản cũ của tài liệu tại NLP 100 Drill Exercises
Chú ý: Khi sử dụng tài liệu 100 bài luyện tập xử lý ngôn ngữ tự nhiên, cần trích dẫn các nguồn sau:
- Tài liệu "言語処理 100 本ノック" của lab Inui-Okazaki, đại học Tohoku, Nhật Bản. URL: http://www.cl.ecei.tohoku.ac.jp/nlp100
- Đường link tới bản dịch hiện tại: https://github.com/minhpqn/nlp_100_drill_exercises. Người dịch: Phạm Quang Nhật Minh.
Footnotes
My reference. ↩